第04章:循环神经网络
- author: zhouyongsdzh@foxmail.com
- date: 2017-08-12
- weibo: @周永_52ML
在斯坦福CS224课程中讲述RNN时,是从NLP中统计语言模型引入的。RNN可以一定程度解决统计语言模型的一些问题。
本章的编排与CS224课程基本类似,先介绍统计语言模型,然后根据语言模型存在的问题引入RNN,最后再根据RNN的问题引出LSTM、GRU等模型。
- 统计语言模型
- 神经语言模型
- 循环神经网络(RNN)
- Long Short Term Memory(LSTM)
- Gated Recurrent Units(GRU)
- Bidirectional RNNs
- Multi-layer RNNs
- 语言模型评估指标
统计语言模型
语言模型是NLP技术中很重要的一环,它是所有NLP的基础,被广泛应用于分词、标注、信息检索、语音识别、机器翻译等任务。
在机器翻译系统中,对于给定的一个英文句子English,需要找到一个使概率$p(Chinese|Englisg)$最大化的中文文本段Chinese,利用贝叶斯公式有:
$$
p(Chinese|English) = \frac{p(English|Chinese) \cdot p(Chinese)} {p(English)}
$$
其中$p(English|Chinese)$为翻译模型,而$p(Chinese)$为语言模型。
语言模型的本质是什么?
简单的说,语言模型是用来计算一个句子概率的概率模型。 一个句子由词序组成,可表示为$x^{(1)}, x^{(2)}, \cdots, x^{(T)}$,则句子出现的联合概率,根据Bates公式可以链式分解为:
$$
\begin{align}
P(x^{(1)},x^{(2)},…,x^{(T)}) \
&= P(x^{(1)}) \times P(x^{(2)} | x^{(1)}) \times \cdots \times P(x^{(T)} | \; x^{(T-1)}, \cdots, x^{(1)}) \\\
&= \prod_{t=1}^{T} P(x^{(t)} | \; x^{(t-1)}, \cdots, x^{(1)})
\end{align}
$$
其中的条件概率$p(x^{(1)}),P(x^{(2)} | x^{(1)}),\cdots$就是语言模型的参数,若这些参数已经全部算得,那么给定一个句子,就可以很快地算出相应的概率了。因此,不同语言模型最大的差异是如何表示和计算条件概率函数。
定义词库集合:$V = \{w_1, w_2, …, w_{V}\}$
如何表示语言模型进而如何得到语言模型的参数呢?常见的方法有n-gram模型、决策树、最大熵模型、最大熵马尔科夫模型、条件随机场、神经网络等。
总结语言模型的思路:语言模型即求句子联合概率 $\rightarrow$ 条件概率函数 $\rightarrow$ 求解方法
n-gram模型
直观地理解,一个词出现的概率与它前面的所有词都有关。如果假定一个词出现的概率只与它前面固定的词相关呢?这就是n-gram模型的基本思想,它做了一个n-1阶的Markov假设:一个词$x^{(t+1)}$出现的概率仅仅与它前面的n-1个词相关。即:
$$
\begin{align}
P(x^{(t+1)} | \; x^{(t)}, \cdots, x^{(1)}) \
&= P(x^{(t+1)} | \; \overbrace { x^{(t)}, \cdots, x^{(t-n+2)}}^{n-1个词}) = \frac{P(x^{(t+1)}, x^{(t)}, \cdots, x^{(x-n+2)})} {P(x^{(t)}, \cdots, x^{(x-n+2)})}
\end{align}
$$
那么,如何获得n-gram和(n-1)-gram的的概率呢?我们可以基于统计假设,在整个文本预料整个统计得到上述公式中的概率。如此,上述公式近似于:
$$
\begin{align}
P(x^{(t+1)} | \; x^{(t)}, \cdots, x^{(1)}) \
&= P(x^{(t+1)} | \; \overbrace { x^{(t)}, \cdots, x^{(t-n+2)}}^{n-1个词}) = \frac{P(x^{(t+1)}, x^{(t)}, \cdots, x^{(x-n+2)})} {P(x^{(t)}, \cdots, x^{(x-n+2)})} \\\
&\approx \frac{ \text{Count}(x^{(t+1)}, x^{(t)}, \cdots, x^{(x-n+2)}) } { \text{Count}(x^{(t)}, \cdots, x^{(x-n+2)}) }
\end{align}
$$
N-Gram模型存在2大问题:一个是稀疏性问题,另一个是存储问题。
稀疏性问题
- 如果$(x^{(t+1)}, x^{(t)}, \cdots, x^{(x-n+2)})$文本从未出现在数据集中呢?那么,上述公式分子为0,通常采用平滑(smoothing)方式;
- 如果$(x^{(t)}, \cdots, x^{(x-n+2)})$为0,那么就采用会回退(backoff)方式,以$(x^{(t)}, \cdots, x^{(x-n+3)})$替代。
从公式中也可以看出,如果n变大,那么这种稀疏性问题只会加剧,通常n不大于5。
事实上,这里涉及到的是一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性,因此需要在可靠性和可区别性之间进行折中。
存储问题
我们要统计训练语料中所有出现的n-gram,增大n或者增加训练预料都会使得模型变得更大。
在介绍如何解决统计语言模型的2大问题前,先介绍下统计语言模型的一个应用。统计语言模型可以用于生成文本(generating text),即给定前k个词,根据n-gram计算方式填充第k+1个词,然后填充第k+2个词,依次下去….。但是这种方式生成的文本可能会极为不通顺、毫无调理(incoherent)。
总结起来,n-gram模型的主要工作是语料中统计各种词串出现的次数以及平滑处理,概率值算好之后存储起来,下次需要计算一个句子的概率时,只需要找到相关的概率参数,将它们连乘起来即可。
然而,机器学习领域通用的逻辑是:对所考虑的问题建模(即模型表达式)后,先为其构造一个目标函数,然后对目标函数进行优化,从而求得一组最优参数,最后利用这组最优参数对应的模型进行预测。
统计模型的目标函数是概率最大似然函数(对应文本的联合概率公式),实际应用中常采用最大对数思然,即把目标函数设为:
$$
\mathcal{L} = \sum_{t=1}^T \log p(x^{(t)}|context(x^{(t)}))
$$
然后对这个目标函数进行最大化。从目标函数公式可见,概率$p(x|context(x))$已被视为关于$x$和$context(w)$的函数,即:
$$
p(x|context(x)) = F(x, context(x), \theta)
$$
其中$\theta$为待定参数集。如此一来,一旦对概率函数$F$进行优化得到最优参数集$\theta^{\star}$后,F也就唯一被确定了,以后任何概率$p(x|context(x))$旧可以通过函数$F(w, context(w), \theta^{\star})$来计算了。很明显,对于这种方法,最关键的地方在于函数$F$的构造了。
神经语言模型
神经语言模型结构比较简单,它首先把每个word向量化表示,然后将输入的n个词concat,中间经过Fully Connect层,最后由Softmax输出下一个词的概率分布。
简单总结神经语言模型结构:${word^{(i)}} \rightarrow emb^{(i)} \rightarrow concat(emb^{(1)}, emb^{(2)}, emb^{(n-1)}) \rightarrow fc \rightarrow softmax$
与n-gram模型对应的是定长窗口(fixed-window)的神经语言模型,它可以解决n-gram模型中存在的稀疏性问题以及无需再存储庞大的参数。此外,最重要的是词语之间的相似性可以通过词向量来体现,有更好的泛化性。
但是,fixed-window神经语言模型也存在几个问题,
- 一是定长窗口通常太小;
- 二是增大窗口fc层参数W同样会增大;
- 三是窗口不能无限增大,
- 最后$x^{(1)}$和$x^{(2)}$are multiplied by completely different weights in . No symmetry in how the inputs are processed.
因此,我们需要一个能处理任意长度的神经网络结构-Recurrent Neural Networks (RNN)。
循环神经网络 (RNN)
经典的RNN模型一个核心的出发点是重复运用同一个参数权重W(如此可使得模型参数较少,也不会随着inputs的变化而变化)。
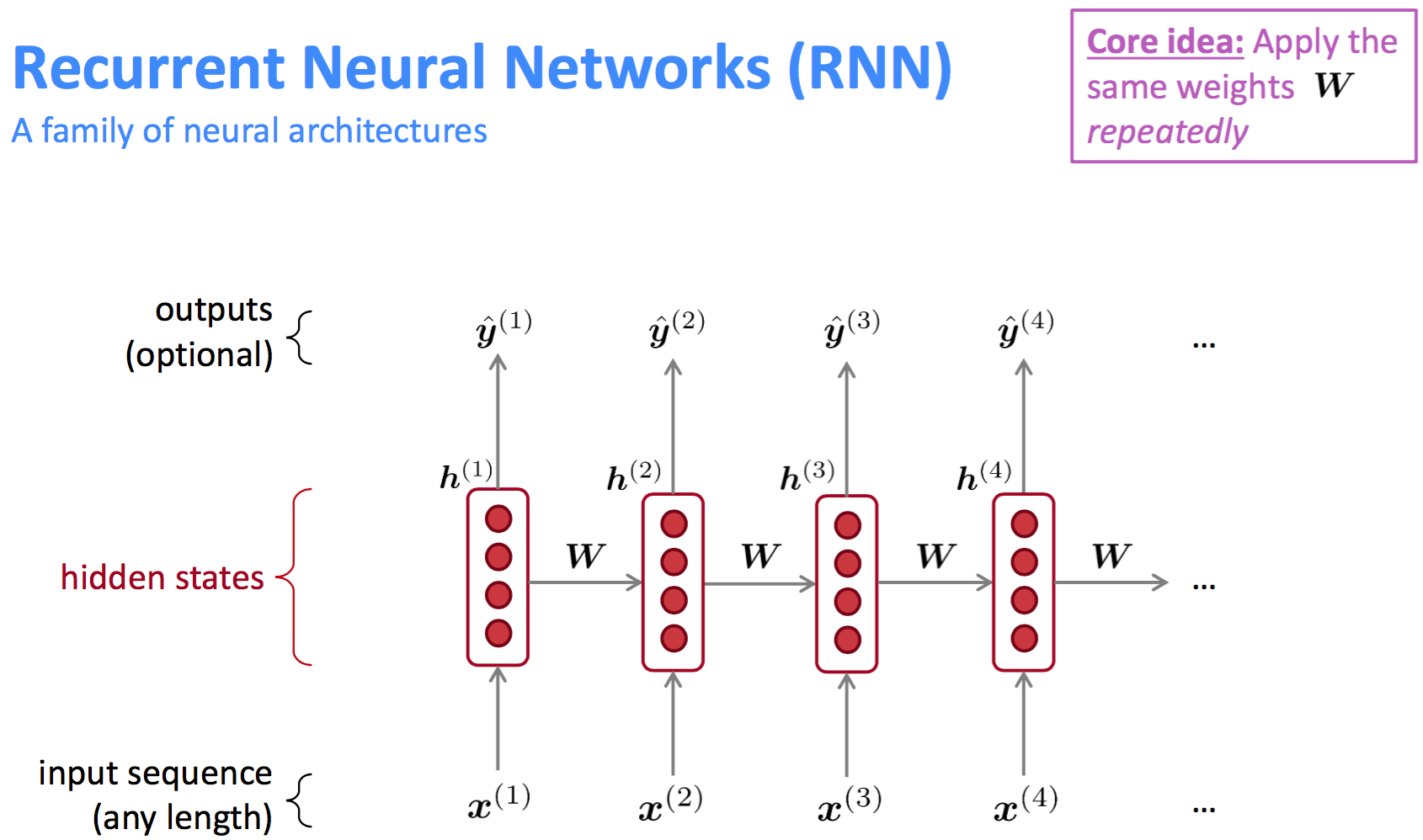
RNN结构
解读RNN模型结构
- 输入层
原始输入word序列,真正训练时会对word做编码;
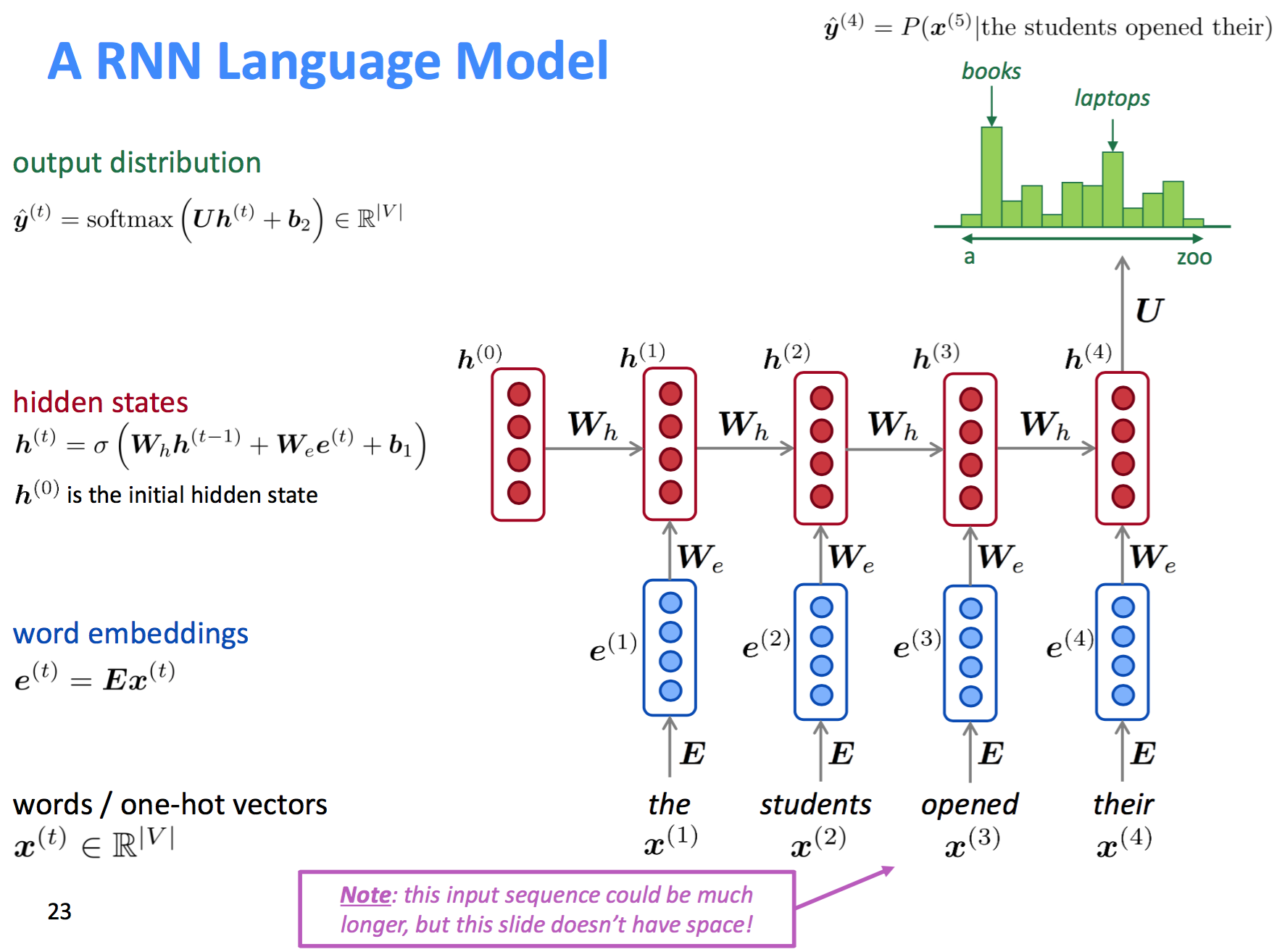
- Embedding层
word的向量化表示,每个词用一个k维的向量表示,即实现$x^{(t)} \rightarrow e^{(t)}$的映射。
- 隐藏状态层(Hidden Status)
RNN的隐层要从两个维度看:1. 针对每一个词的embedding,$e^{(t)}$有对应的共享参数$W_e$和$b_1$;2. 词序方向,有对应的共享参数$W_h$。那么,每一个词的隐层输出$h^{(t)}$既与该词的$e^{(t)}$有关,也与前一个词的隐层输出$h^{(t-1)}$有关。公式表示如下:
$$
h^{(t)} = \sigma(W_h h^{(t-1)} + W_e e^{(t)} + b_1)
$$
其中$h^{(0)}$为初始隐层状态(需要初始化),$\sigma$是激活函数。
疑问:$h^{(t)}$等各维度shape通常是多大?$h^{(0)}$如何初始化?$\sigma$表达式?
- 输出层
同样对应一组参数$U$和$b_2$,公式表示如下:
$$
\hat{y}^{(t)} = \text{softmax} \, (h^{(t)} U + b_2)
$$
到这里,RNN模型结构解读完了,比较容易理解。我们看下RNN的优缺点有哪些:
| 模型 | 优点 | 缺点 |
|---|---|---|
| RNN | 1. 能够处理任意长度的输入(相对fixed-window)且模型大小固定 2. 对于第$t$步的计算理论上可以使用前面很多步的信息 3. 对称性?Same weights applied on every timestep, so there is symmetry in how inputs are processed. |
1. 循环网络结构计算太慢; 2. 实际中,模型很难学到前面多步反馈的信息,存在因梯度消失导致的信息丢失问题; |
下面我们介绍RNN模型参数是如何学习和训练的?
RNN模型参数学习
训练RNN模型的文本语料数据表示为一个很长的词序列$x^{(1)}, \cdots, x^{(T)}$ ($T$为文本长度)。依次喂给RNN模型并计算第$t$步的输出概率分布($t=1,\cdots,T$),每一步的损失函数为交叉熵损失。公式表示如下:
$$
J^{(t)}(\theta) = CE(\hat{y}^{(t)}, h^{(t)}) = - \sum_{w \in W} y_w^{(t)} \text{log} \hat{y}_w^{(t)} = - \text{log} \hat{y}_{x^{(t+1)}}^{(t)}
$$
那么对于整个训练预料来说,损失函数为:
$$
J(\theta) = \frac{1}{T} \sum_{t=1}^{T} J^{(t)}(\theta) = - \frac{1}{T} \sum_{t=1}^{T} \text{log} \hat{y}_{x^{(t+1)}}^{(t)}
$$
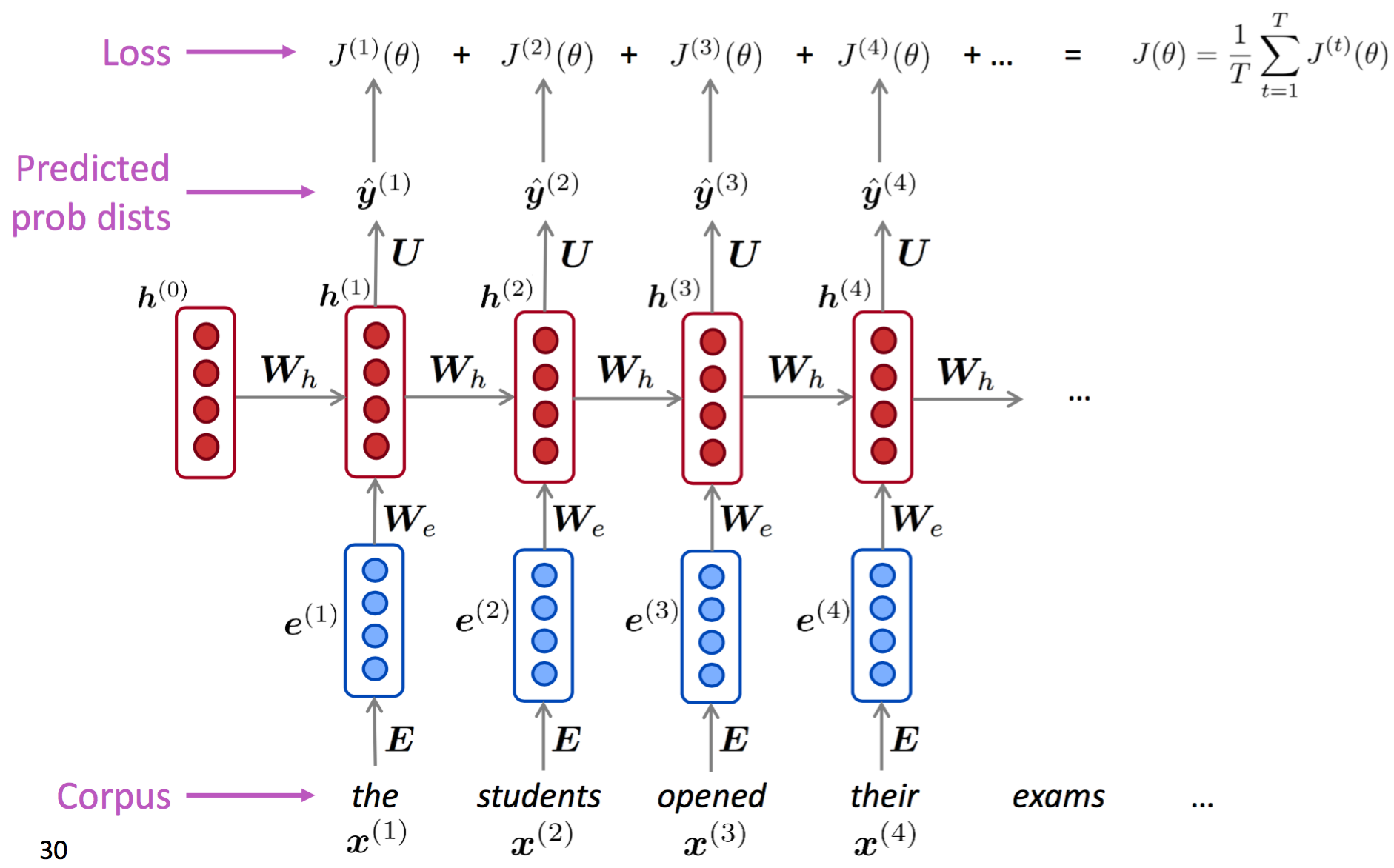
然而,如果在全局预料中计算损失和梯度时间成本太高。在实践中$x^{(1)}, \cdots, x^{(T)}$多表示为一个句子或一篇文档。可以在batch数据上计算损失函数并用梯度下降更新模型参数。
RNN模型反向传播
反向传播我们重点关注以下几个点:
- 隐状态层的共享权重参数$W_h$的倒数如何求?如下图:
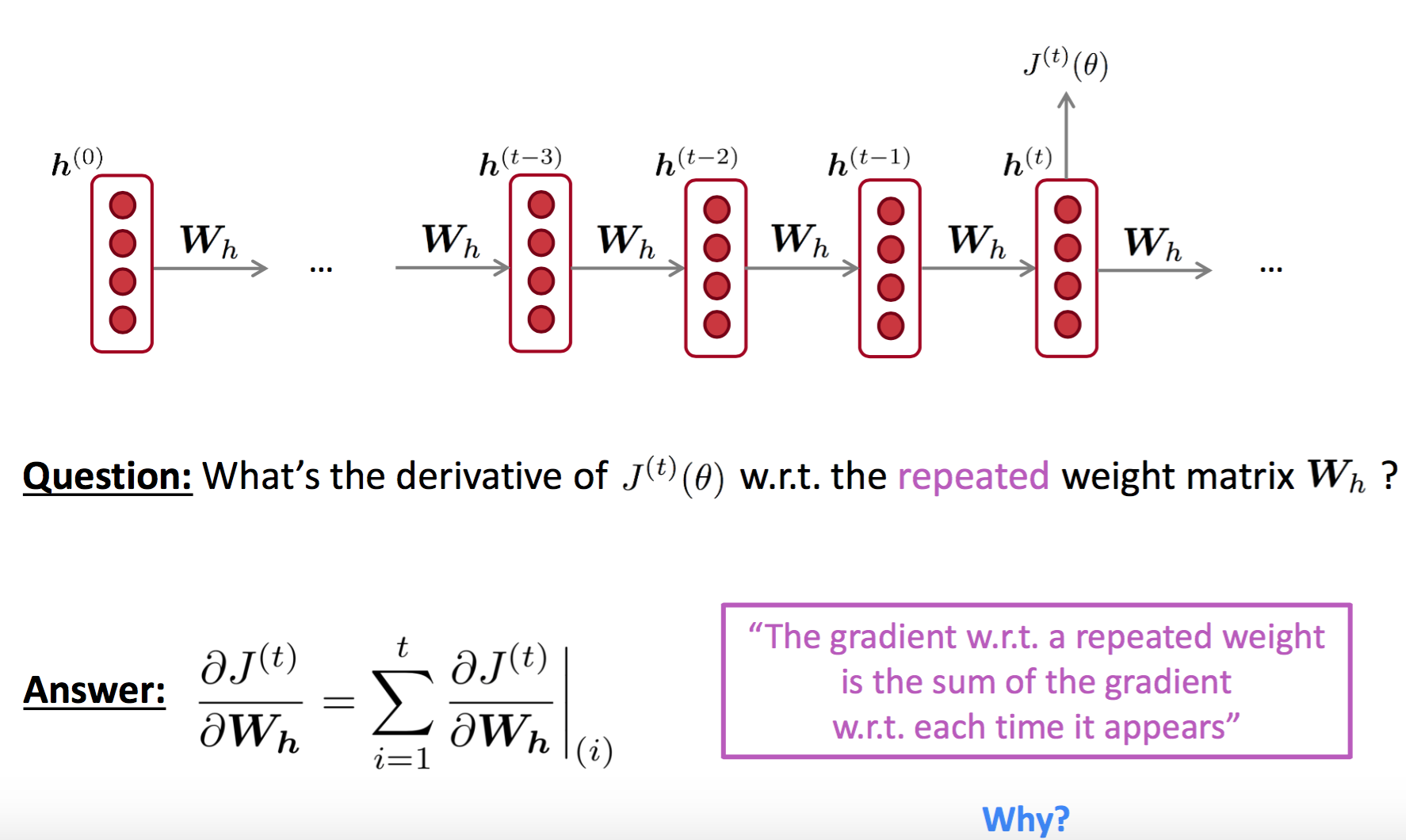
根据多变量链式法则,一个变量的梯度等于下游多个函数对其求导结果的累加和。公式表示为:
$$
\frac{\partial J^{(t)}(\theta)} {\partial W_h } = \sum_{i=1}^{t} \frac{\partial J^{(t)} (\theta)} {\partial W_h} \vert_{(i)}
$$
我们可以看到,权重参数$W_h$的梯度对应的计算有$(1+2+\cdots+T)=\frac{1}{2}T(T+1)$次($T$表示语料长度),梯度的计算复杂度是$O(T^2)$。
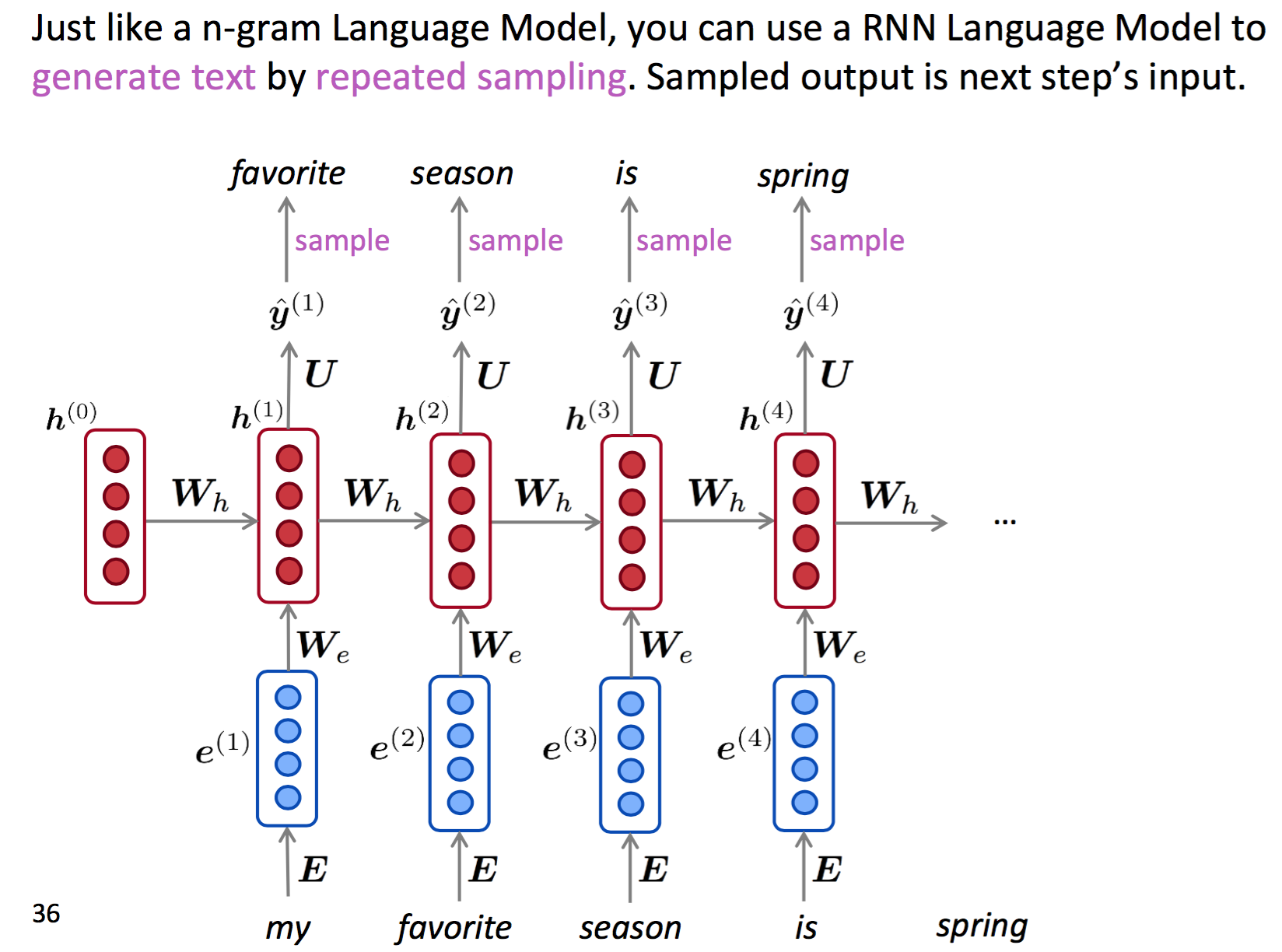
RNN应用-文本生成
类似统计语言模型,RNN模型也可用于生成文本(对预测结果进行重复采样)。
语言模型评估指标
评估语言模型效果的方式是困惑度(perplexity)。公式表示为:
$$
\begin{align}
perplexity &= \prod_{t=1}^{T} \left(\frac{1} {P_{LM}(x^{(t+1)}|x^{(t)},\cdots,x^{(1)})}\right)^{\frac{1}{T}} \\\
&= \prod_{t=1}^{T} \left(\frac{1} {\hat{y}_{x_{t+1}}^{(t)}}\right)^{\frac{1}{T}} = \exp \left(\frac{1}{T} \sum_{t=1}^T -\log \hat{y}_{x_{t+1}}^{(t)} \right) = \exp(J(\theta))
\end{align}
$$
可以看到,表达式是语言模型概率公式的倒数,指数$\frac{1}{T}$作用是词数作归一化。上式等价于语言模型损失函数的指数。所以perlexity越小,说明语言模型效果越好。
RNN存在的问题
RNN模型从参数学习的角度看,最大的问题是存在梯度消失的问题(gradient vanish)。根据链式法则,第$t$步的损失函数对第一个隐藏状态层$h^{(1)}$求导时,可以看到:
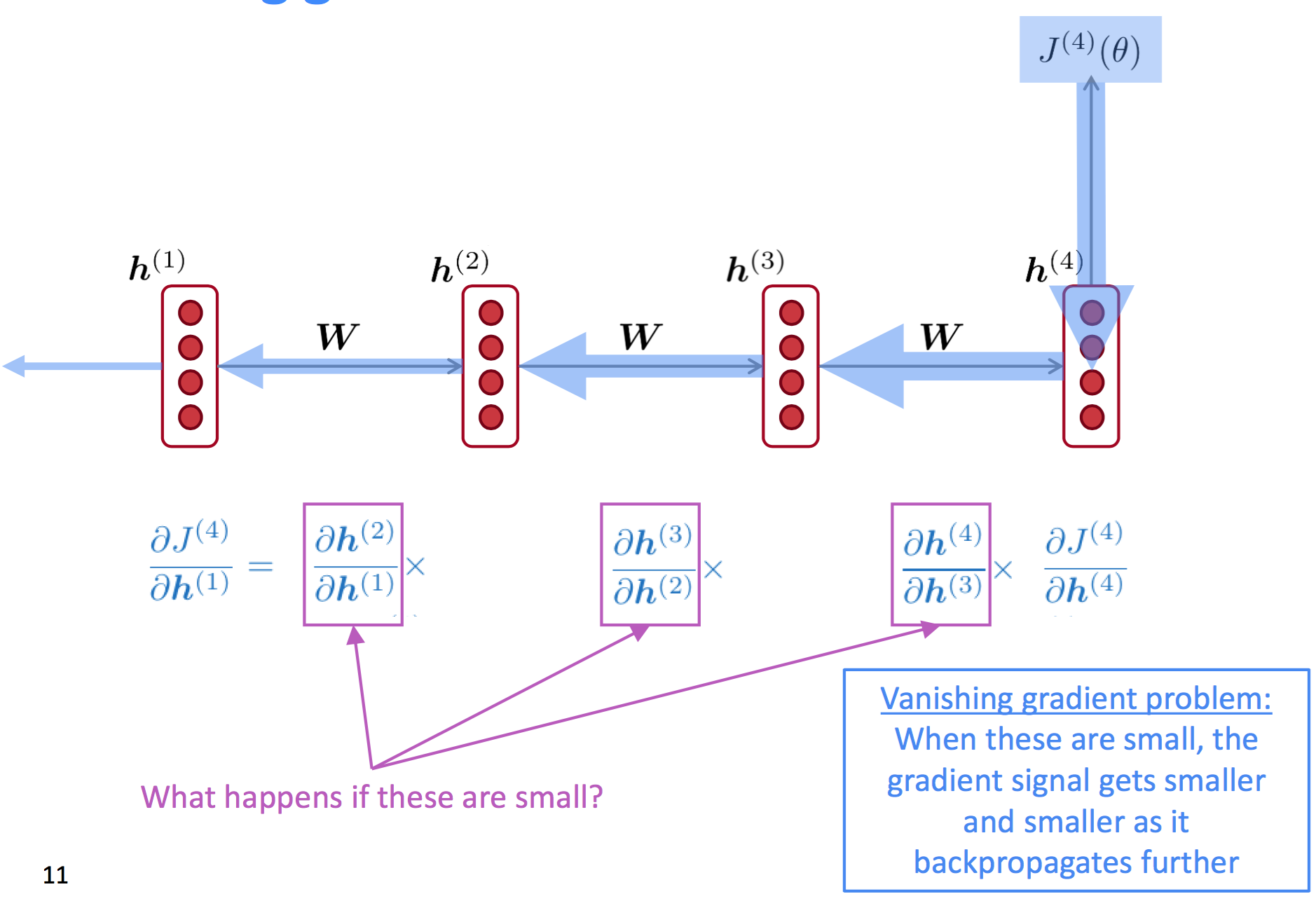
RNN模型结构中提到的$h^{(t-1)}$到$h^{(t)}$的函数表达式为$h^{(t)} = \sigma(W_h h^{(t-1)} + W_x x^{(t)} + b)$,根据链式法则可得$\frac{\partial h^{(t)}} {\partial h^{(t-1)}} = \text{diag} \left(\sigma^{‘} (W_h h^{(t-1)} + W_x x^{(t)} + b) \right) \cdot W_h$。
如果$\frac{\partial h^{(t)}} {\partial h^{(t-1)}}$很小会怎样呢?就会导致梯度信号随着反向传播的过程越来越弱,直至出现梯度消失。
下面简要给出梯度消失的证明过程:考虑第$i$步的损失函数$J^{(i)}(\theta)$,它对应的前面第$j$步的隐藏状态层为$h^{(j)}$,那么可得$J^{(i)}(\theta)$对$h^{(j)}$的导数为:
$$
\begin{align}
\frac{\partial J^{(i)}(\theta)} {\partial h^{(j)}} &= \frac{\partial J^{(i)}(\theta)} {\partial h^{(i)}} \prod_{j < t \le i} \frac{\partial h^{(t)}} {\partial h^{(t-1)}} \\\
&= \frac{\partial J^{(i)}(\theta)} {\partial h^{(i)}} \cdot W_{h}^{(i-j)} \cdot \prod_{j < t \le i} \text{diag} \left(\sigma^{‘} (W_h h^{(t-1)} + W_x x^{(t)} + b) \right)
\end{align}
$$
如果$W_h$比较小(如最大特征值小于1),那么随着$i$和$j$之间的距离越来越大,整体的梯度也就越来越小(指数衰减),最终趋于消失。如果$W_h$特征值大于1,那么梯度会指数级爆炸(exploding gradient)。
考察问题:
- RNN训练时存在梯度消失的情况,是否存在梯度爆炸的情况?存在
- 如何通过公式证明RNN会存在梯度消失(或梯度爆炸)的问题,随着term距离越来越大时?
为什么梯度消失是一个问题?(Why is vanishing gradient a problem?)
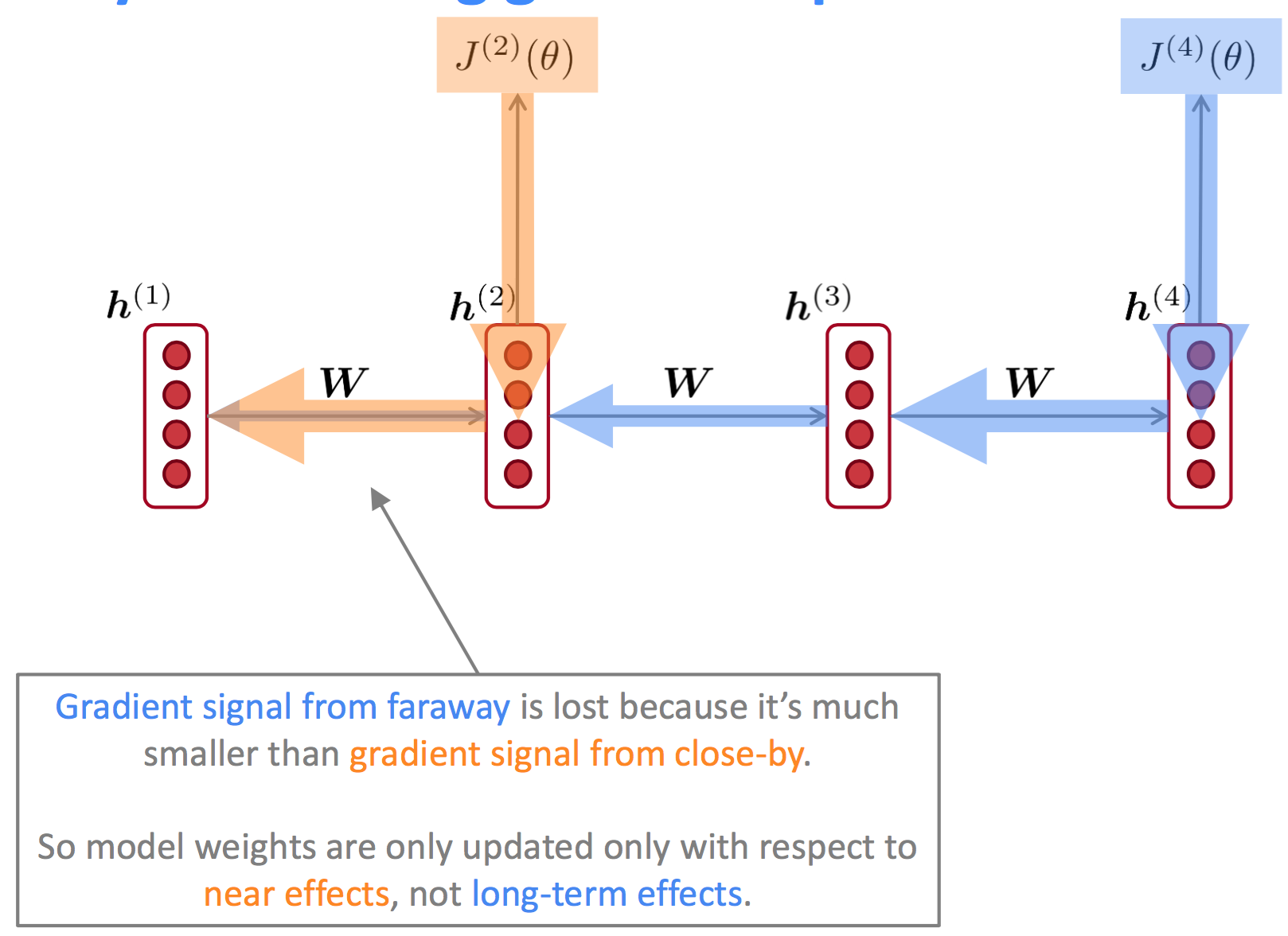
从上图可以看到,从远处传递过来的梯度信号强度远弱于近处的梯度信号,那么模型参数$W_h$的更新主要受近处梯度的影响,与long-term无关。
我们也可以从另一个角度解释,梯度是过去对影响未来的一种度量方式,如果梯度因为距离过长导致消失的情况,我们无法得知:
- $t$与$t+n$步对应的term是否真的没有依赖关系;
- 无法得到正确的参数(wrong parameters)来捕捉$t$与$t+n$步之间真实的依赖关系;
为什么梯度爆炸是一个问题?(Why is exploding gradient a problem?)
如果gradient很大,以SGD优化算法更新参数为例:
$$
\theta_{new} \leftarrow \theta_{old} - \overbrace{\alpha}^{\text{learning rate}} \cdot \underbrace{\nabla_{\theta} J(\theta)}_{\text{gradient}}
$$
梯度过大可能导致:1. 跳过最优解;2. 更坏的情况是出现NaN或Inf,不得不重新训练;
解决梯度爆炸的一种方法是梯度截断(Gradient Clipping),即当梯度大于阈值时,取该阈值。直观的理解就是参数更新时保持方向不变,但是减小更新参数的步幅。
梯度爆炸有比较直观的解决方案,那么梯度消失问题如何解决呢?
经典的RNN模型,学习很多步之前的信息是比较困难的,因为隐层的状态是一个递归的过程,无法保存长期信息。
那么,是否可以将长短期信息分开存储并记忆呢?下面讲到的LSTM可以实现这种功能。
Long Short-Term Memory(LSTM)
LSTM(长短期记忆网络)在对序列问题建模时,每一步用两个状态表示:隐藏态$h^{(t)}$(hidden status)和细胞态$c^{(t)}$(cell status)。它们都是长度为n的向量,cell status存储长期的信息,LSTM算法可以抹擦、写、读细胞态中的信息。
cell status中哪些信息被抹擦、写、读是由相应的门(gate)来控制的,分别对应遗忘门、输入门、输出门。
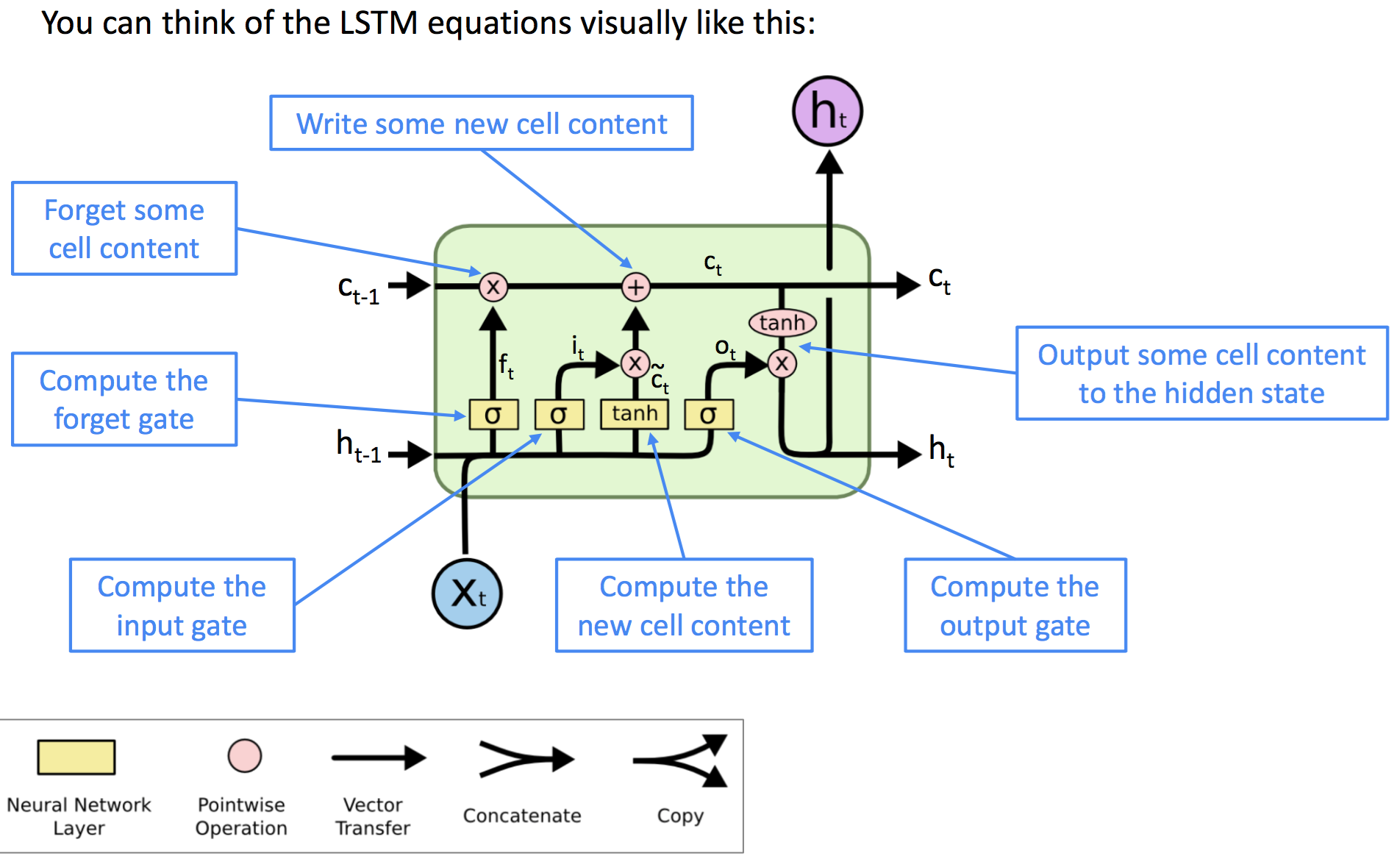
LSTM结构用公式表示为:
$$
\begin{align}
f_t &= \sigma(W_f h^{(t-1)} + U_f x^{(t)} + b_f) \quad // 计算遗忘门(得到旧cell内容占比) \\\
i_t &= \sigma(W_i h^{(t-1)} + U_i x^{(t)} + b_i) \quad // 计算输入门(得到新cell内容占比) \\\
\tilde{c_t} &= \tanh(W_c h^{(t-1)} + W_c x^{(t)} + b_c) \quad // t状态的新细胞内容,取值[-1,1] \\\
c_t &= f_t \circ c_{t-1} + i_t \circ \tilde{c_t} \quad // 更新细胞内容,得到新细胞状态(类似权重衰减)\\\
o_t &= \sigma(W_o h^{(t-1)} + W_o x^{(t)} + b_o) \quad // 计算输出门(细胞状态权重) \\\
h_t &= o_t \circ \tanh(c_t) \quad // 输出一些细胞内容作为隐藏态
\end{align}
$$
考察:LSTM结构是怎样的?画结构图并给出表达式
问题:LSTM是如何解决梯度消失问题的?
相对于经典的RNN模型,LSTM更容易保留前面状态的信息。如果遗忘门(forget gate)设置为0,那么每一步全部的信息都被记忆,那么cell state就可以保留无限的信息。而RNN通过学习递归的权重矩阵$W_h$来实现这一功能还是较困难的。
需要注意的是,LSTM也不能保证不出现梯度消失或梯度爆炸问题,它最大的优势就是在模型层面提供了一种比较容易的方式可以学习long-distance依赖信息。
在2013~2015年间,LSTM算法在许多领域均取得了很大的成功,如手写字识别、语音识别、机器翻译、解析器、图像解读(image captioning)等。目前(2018年)Transformer在这些领域成为了主要的技术。
一段话描述LSTM模型结构:LSTM模型是在RNN基础上引入了cell state用来保存长期信息,同时又引入3个门来实现信息的控制,即forget gate和input gate分别控制信息的保留和传入,output gate确定新cell中的哪些信息被输出。
Gated Recurrent Units (GRU)
GRU(门控递归单元)是2014年由Cho et al提出,它可以理解为是LSTM模型的简单实现。GRU在每一步$t$的输入只有$x^{(t)}$和$h^{(t)}$,没有细胞态(cell state)。GRU模型单元结构示意图如下:
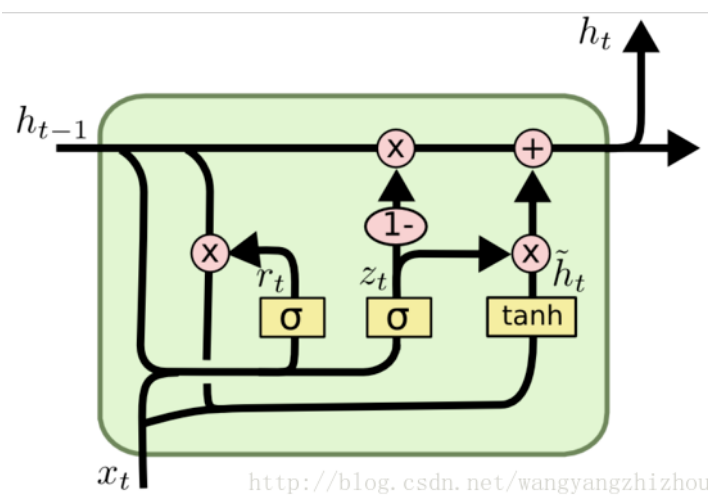
- 重置门(Reset)
重置门用来控制前隐层状态$h^{(t-1)}$参与计算新内容的比例,相当于LSTM中遗忘门和输入门的结合。表达式为:$r^{(t)} = \sigma \left(W_r h^{(t-1)} + U_r x^{(t)} + b_r\right)$
- 更新门(Update Gate)
更新门用来控制前隐层状态$h^{(t-1)}$被保留的比例。表达式为:$u^{(t)} = \sigma \left(W_u h^{(t-1)} + U_u x^{(t)} + b_u \right)$
- 新隐层状态内容(New hidden state content)
重置门选择了前隐层状态中有用的信息,并结合当前输入$x^{(t)}$来计算新隐层状态内容。表达式为:$\tilde{h}^{(t)} = \tanh \left(W_h (r^{(t)} \cdot h^{(t-1)}) + U_h x^{(t)} + b_h\right)$
- 隐层状态(Hidden state)
最后,更新门控制哪些隐藏状态被保留,并且更新到隐层状态内容上。表达式为:$h^{(t)} = (1 - u^{(t)}) h^{(t-1)} + u^{(t)} \tilde{h}^{(t)}$
问题:GRU是如何解决梯度消失问题的?
类似LSTM,GRU通过控制update gate来保存long-term信息的($u^{(t)})$。
研究者们提出了很多门控RNN的变种,其中LSTM和GRU最为广泛使用。二者最大的区别是GRU计算更快且参数更少。如果有大量的训练数据或数据中存在长依赖的信息,LSTM是很好的选择。
是否只有RNN存在梯度消失或爆炸问题呢?显然不是,前馈神经网络、卷积神经网络都可能存在,尤其是在一个维度方向增加层数。由于反向传播时非线性函数的链式反则,梯度可能逐渐变小甚至消失。可以在深度前馈或卷积结构中添加direct connections,比如ResNet, DenseNet, HighWayNet等结构都针对可能出现梯度消失的情况添加了一些操作。
除了上述介绍的RNN、LSTM、GRU等模型结构外,下面介绍两个重要的RNN变种:Bi-directional RNNs和Multi-layer RNNs。
Bidirectional RNNs
双向RNN模型结构如下图所示:
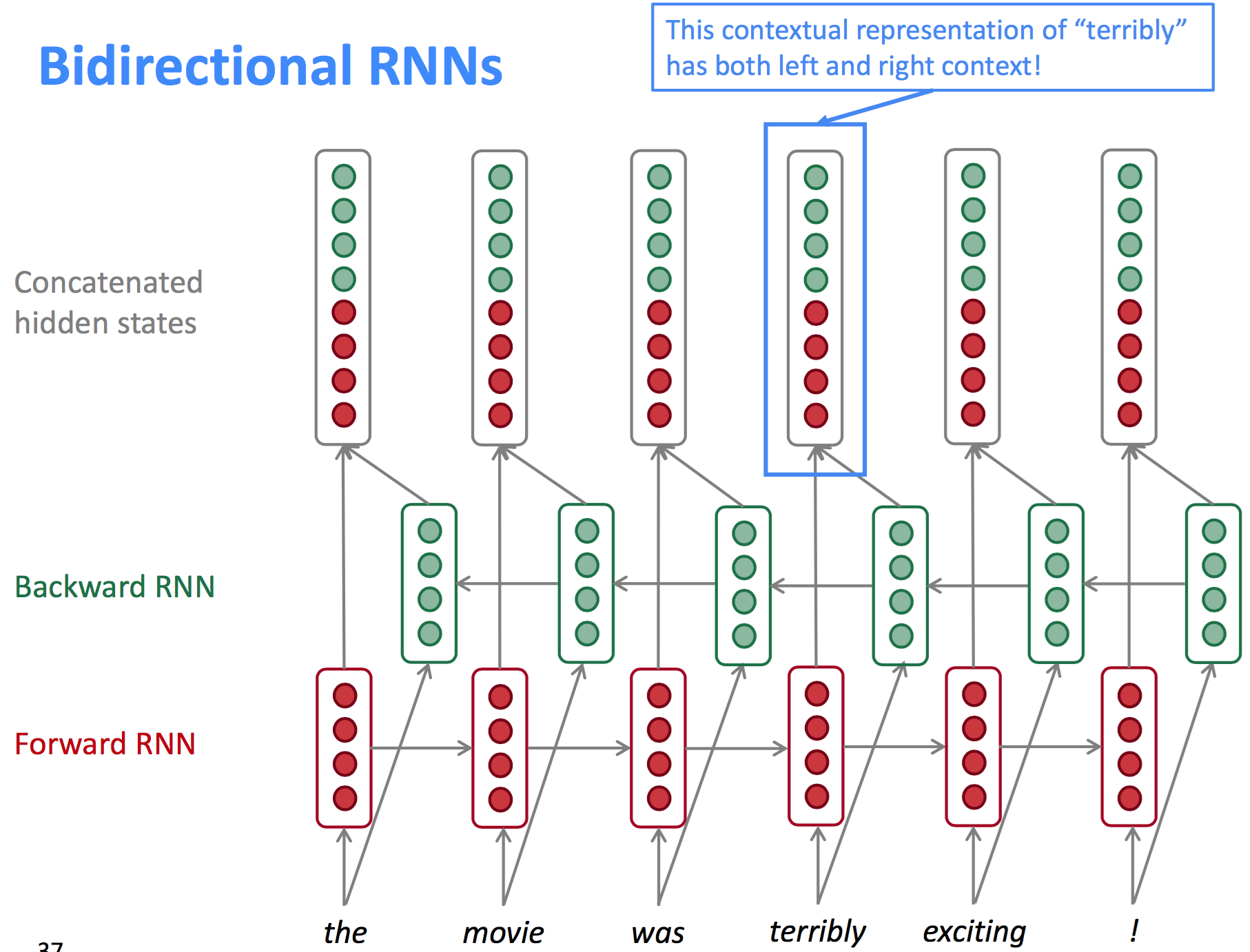
以情感分类问题为例,给定一个完整的句子或段落,情感表达不一定是词的单向表示,也可能是双向的。在$t$步时的模型结构表达式为:
$$
\begin{align}
\overrightarrow{h}^{(t)} &= \text{RNN}_\text{FW}(\overrightarrow{h}^{(t-1)}, x^{(t)}) \qquad // 前向RNN \\\
\overleftarrow{h}^{(t)} &= \text{RNN}_\text{BW}(\overleftarrow{h}^{(t-1)}, x^{(t)}) \qquad // 反向RNN \\\
h^{(t)} &= [\overrightarrow{h}^{(t)}, \overleftarrow{h}^{(t)}] \qquad // concat
\end{align}
$$
注意,双向RNN仅适合用于完整输入序列内容的场景,不适合单向序列任务的场景,如语言模型(LM仅知道左边的信息,不知道右边的信息)。当前BERT模型(基于Transformer的双向Encoder表示)效果好于双向RNN模型。
这里的RNN单元也可以是LSTM或GRU等单元。
Multi-layer RNNs
经典的RNN模型是隐层单元沿着一个维度方向的深度模型,如果扩展到另外一个维度,那么得到的就是多层RNN模型。lower RNNs表示的是低阶特征信息,higher RNNs表示高阶特征信息。结构如下:
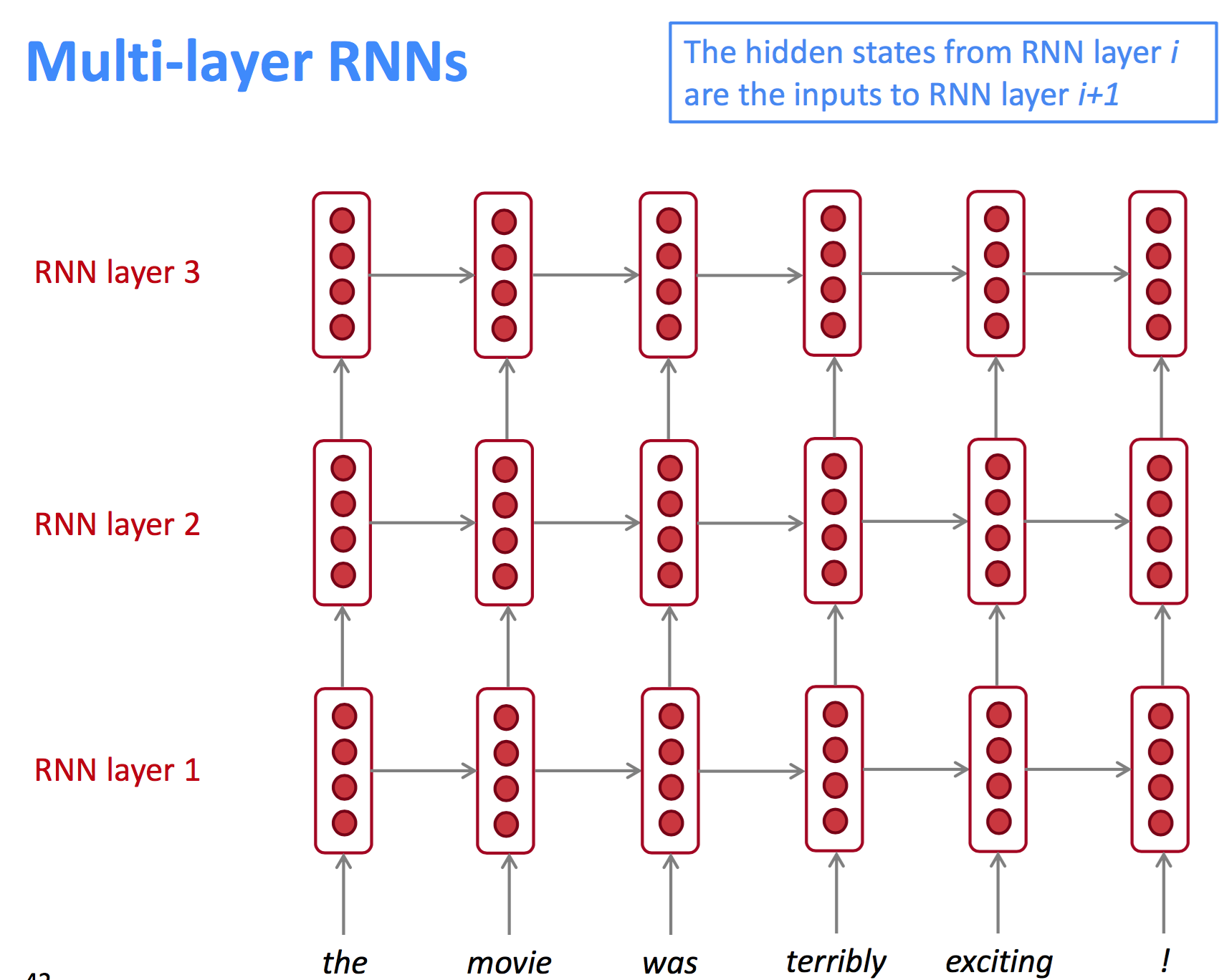
效果好的RNN结构通常是多层的,2017年有人研究得出结论:神经机器翻译中,使用2~4层encoder RNN和4层decoder RNN效果最好。目前(2018年),基于Transformer的网络模型(如BERT)使用了24层结构。