第07章:Attention机制与Transformer
- author: zhouyongsdzh@foxmail.com
- date: 2018-03-01
- weibo: @周永_52ML
本章关键词:Attention、Feed-Forward NN, Encoder, Decoder, Transformer等
写在前面
Attention机制早在图像识别领域展露头脚,近些年来在机器翻译和文本分类领域也得到了广泛的应用,并且取得了很好的性能。
本章要讲的注意力机制和Transformer的内容,主要来自论文《Attention is all you need》,除了论文外,还有一篇总结很好的博客The Illustrated Transformer,因此本章的内容主要参考以上论文和博客,并在此基础上进一步完善其内容。
如果读英文资料不吃力的朋友,强烈建议读以上文章和博客。因此本章内容对细节的阐述不及上述资料。
Attention
Attention机制为什么有效果?其方法背后的物理意义是什么?
以NLP机器翻译问题为例,机器翻译是以及Encoder-Decoder框架为主体的技术。Encoder阶段的输入是一个句子序列(each word in input sentence),每个word用一个embedding向量表示,因此输入是一个a list of embedding vector。
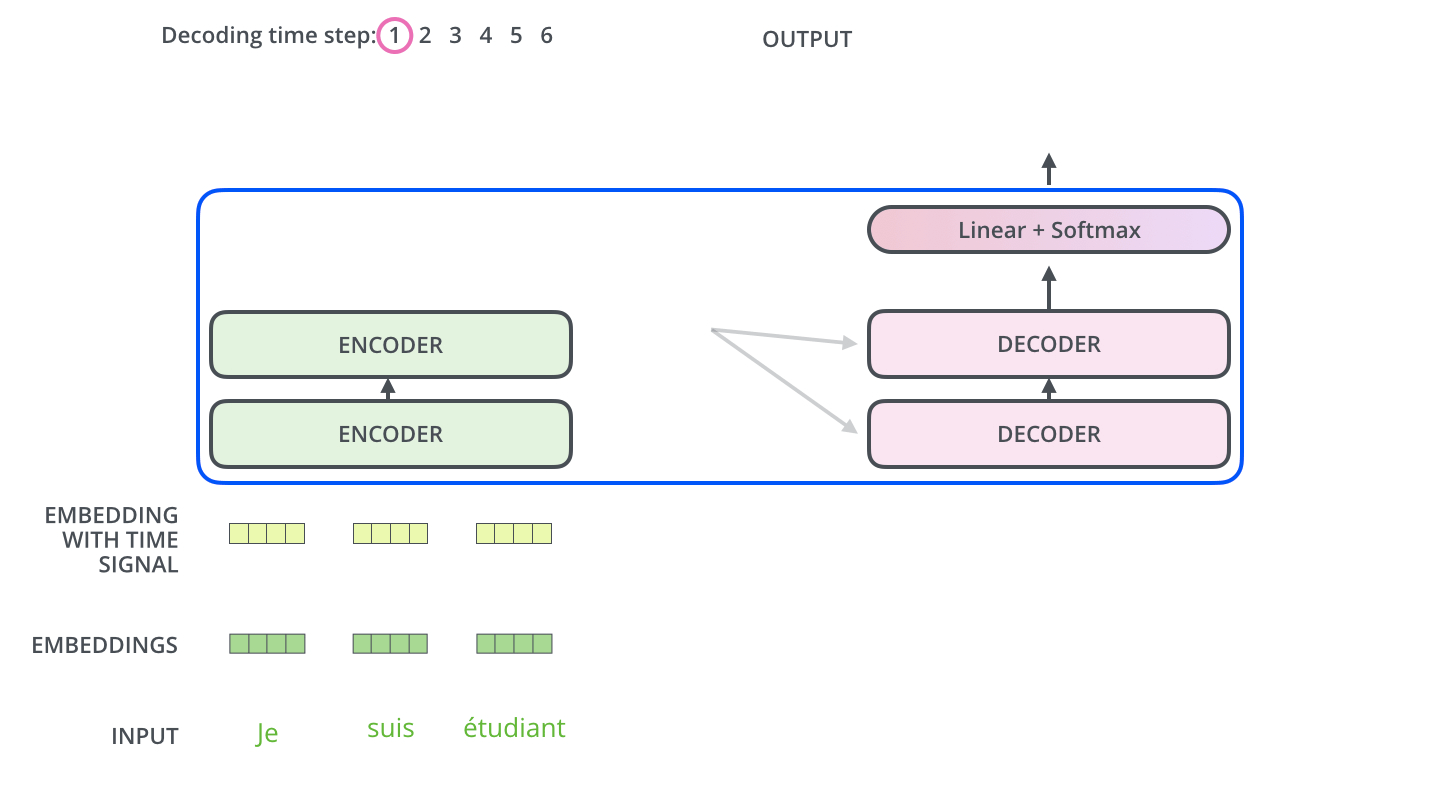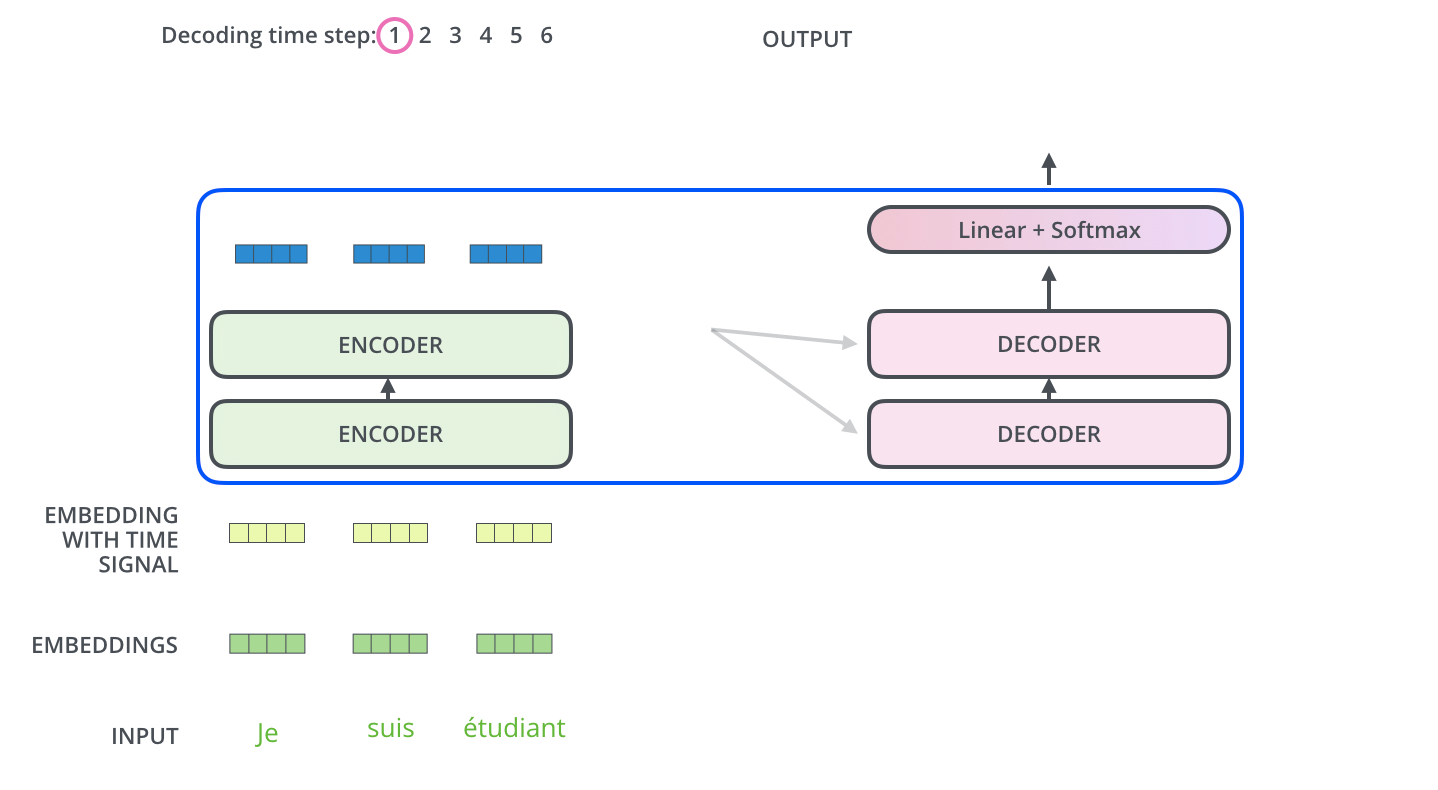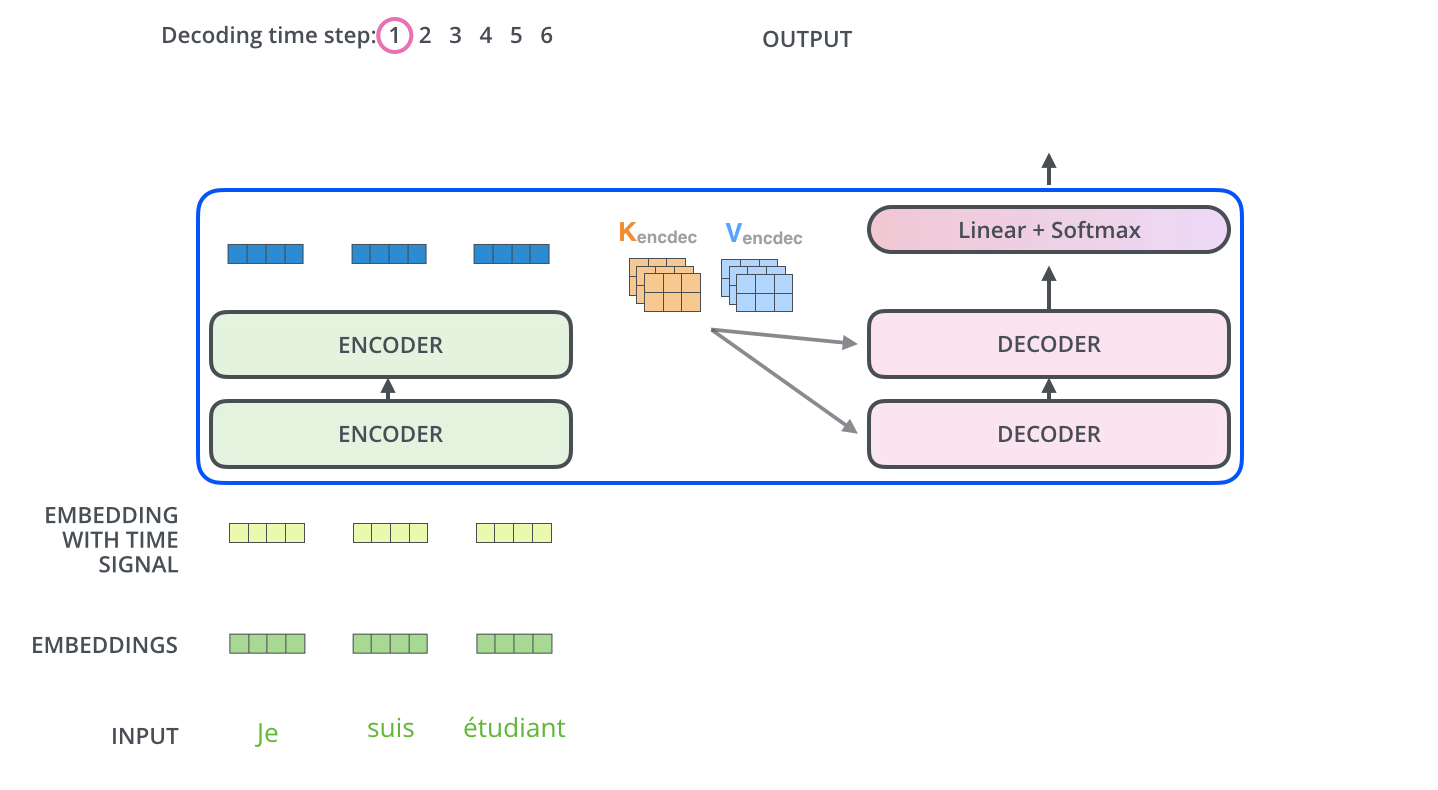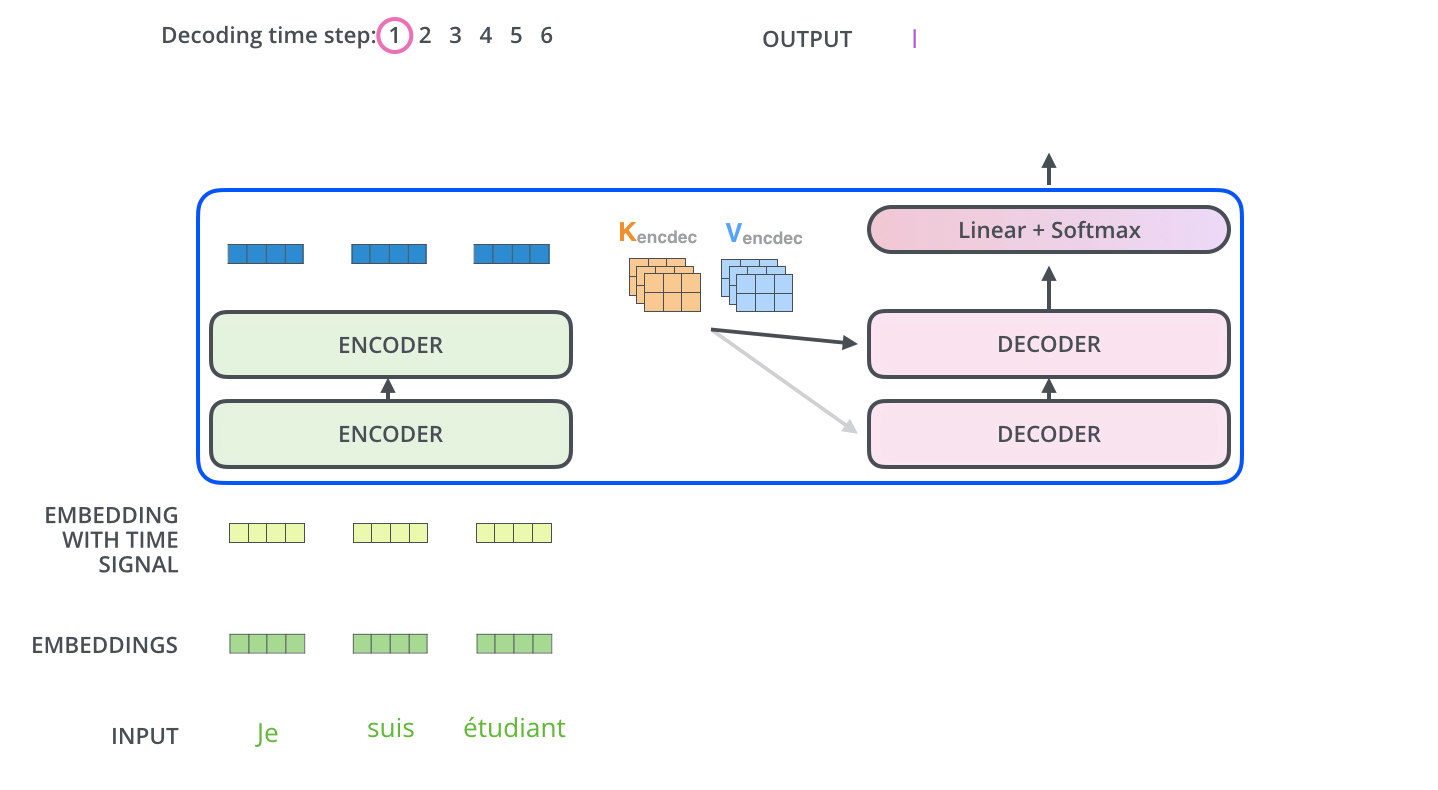
self-attention的目的是学习输入句子中每个词的重要程度(注意力权重分布),然后将其与每个词的value相乘,得到attention的输出。 之所以称之为self,是因为query和key-value均来自同一个输入(在transformer decoder阶段attention输入可以看到query来自上游decoder的输出,key-value来自encoder的输出。)
在NLP中,self attention通常作用是计算句子中每个单词的重要程度。
Self Attention
self-attention的输入输出维度可以不一样吗?
答:可以不一样。
假设输入有n个embedding,embedding长度为$d_k$,那么输入用矩阵可表示为$X \in R^{n \times d_k}$,3个中间变量$W^Q, W^K, W^V \in R^{d_k \times d_{k’}}$,$d_{k’}$为attention输出维度。self attention表达式如下:
$$
\begin{align}
Q &= X \cdot W^Q \\\
K &= X \cdot W^K \\\
V &= X \cdot W^V \\\
\textbf{attention}(Q,K,V) &= \text{Softmax} \left(\frac{QK^T}{\sqrt{d_k}} \right) \cdot V
\end{align}
$$
attention的表达式可以理解为一种映射:query在key-value pairs中的映射。也可以理解为一种soft的key找value,因此也有人把attention公式表述为:
$$
\textbf{Attention(Query, Sources)} = \sum_{k=1}^K \textbf{Similarity}(Query, Key_i) \cdot Value_i
$$
Multi-head Attention
Multi-head attention的作用是什么?与self attention的优势比较 优势在哪儿?
类似于CNN中同一个卷积层使用多个卷积核的思想一样,原文在同一multi-head attention层中使用8个scaled dot-product attention,输入同时是QKV, 进行注意力的计算,彼此之间参数不共享,最终concat到一起。这样就允许模型在不同的子空间中学习相关的信息,主要目的是抽取更加丰富的特征信息。
此外,有资料显示,不同层下的多头 分布有一定的差异。初始时差异较大,随着层数增加,多头的方差变小,最终收敛;
解释参考:multi head attention解读
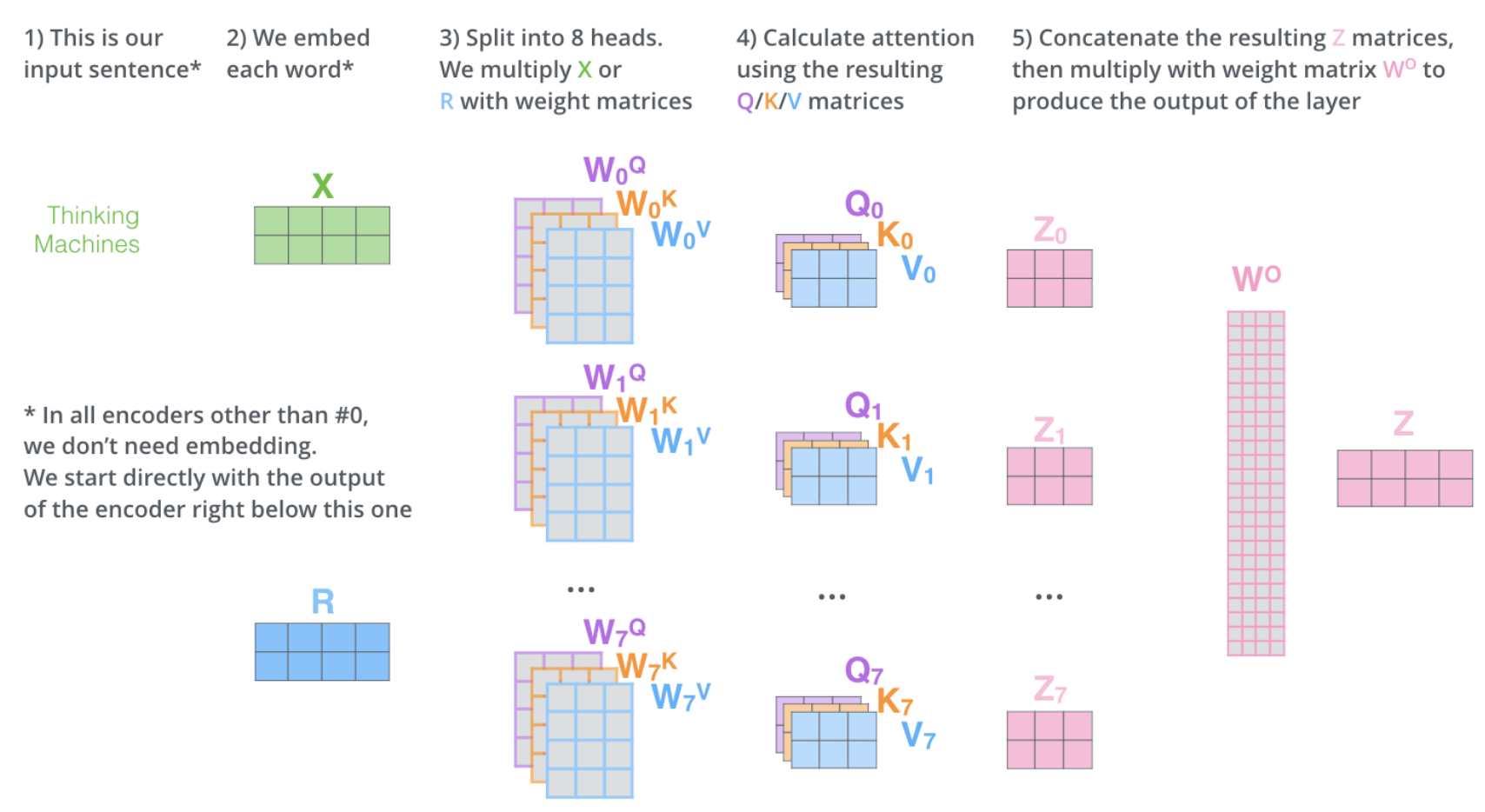
Transformer
Transformer结构
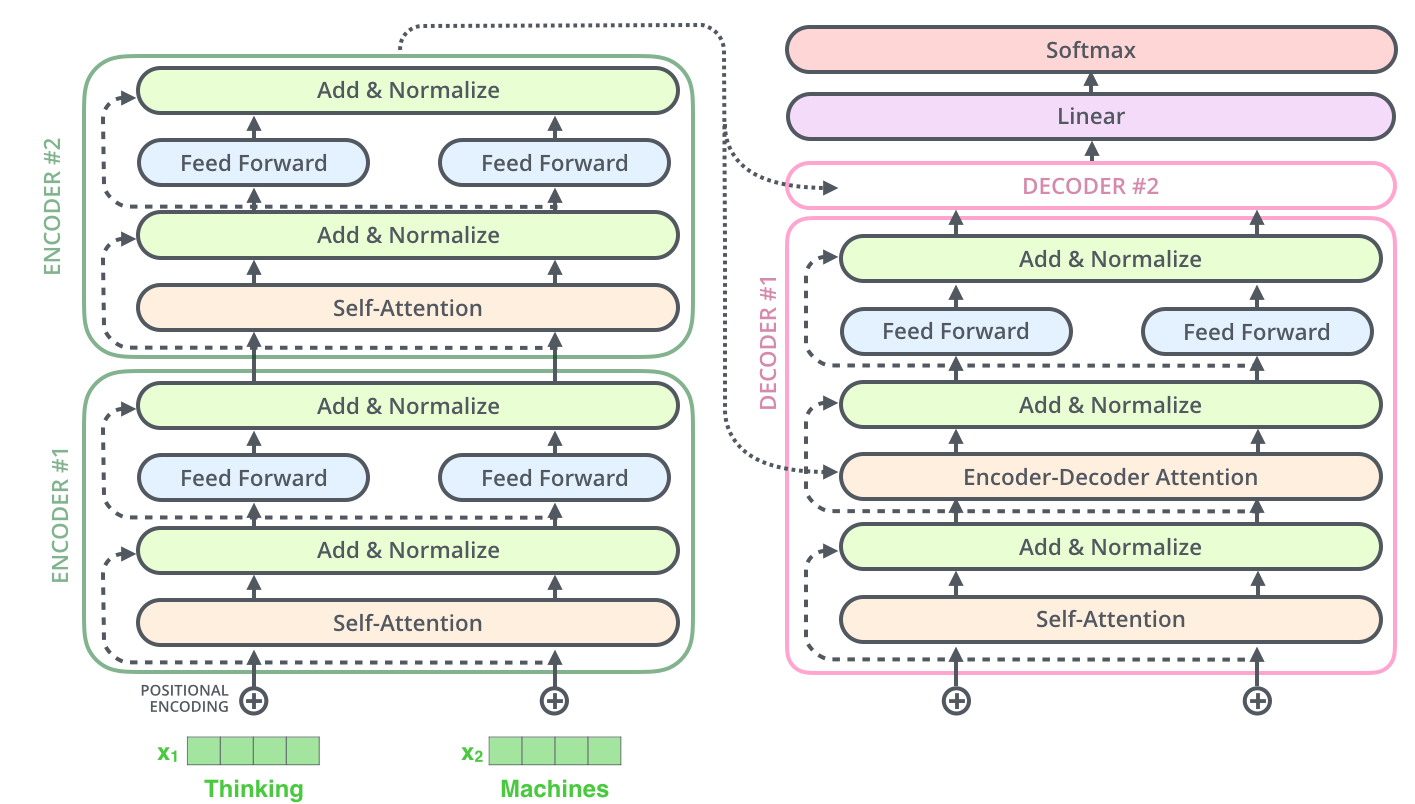
Encoder阶段
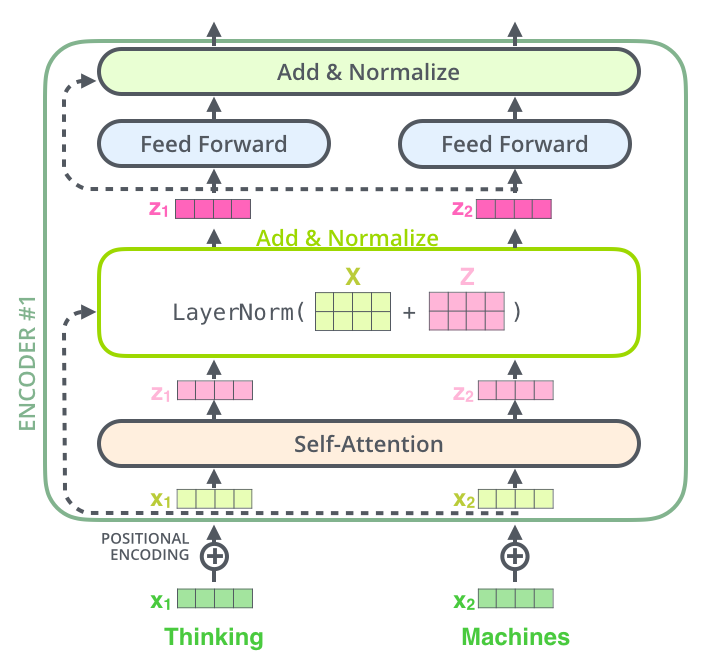
由多个sub-layers组成,每个sublayers结构是一样的,均包含self attention或multi-head attention,feed-forward neural network, residual connection, layer normalization四部分。
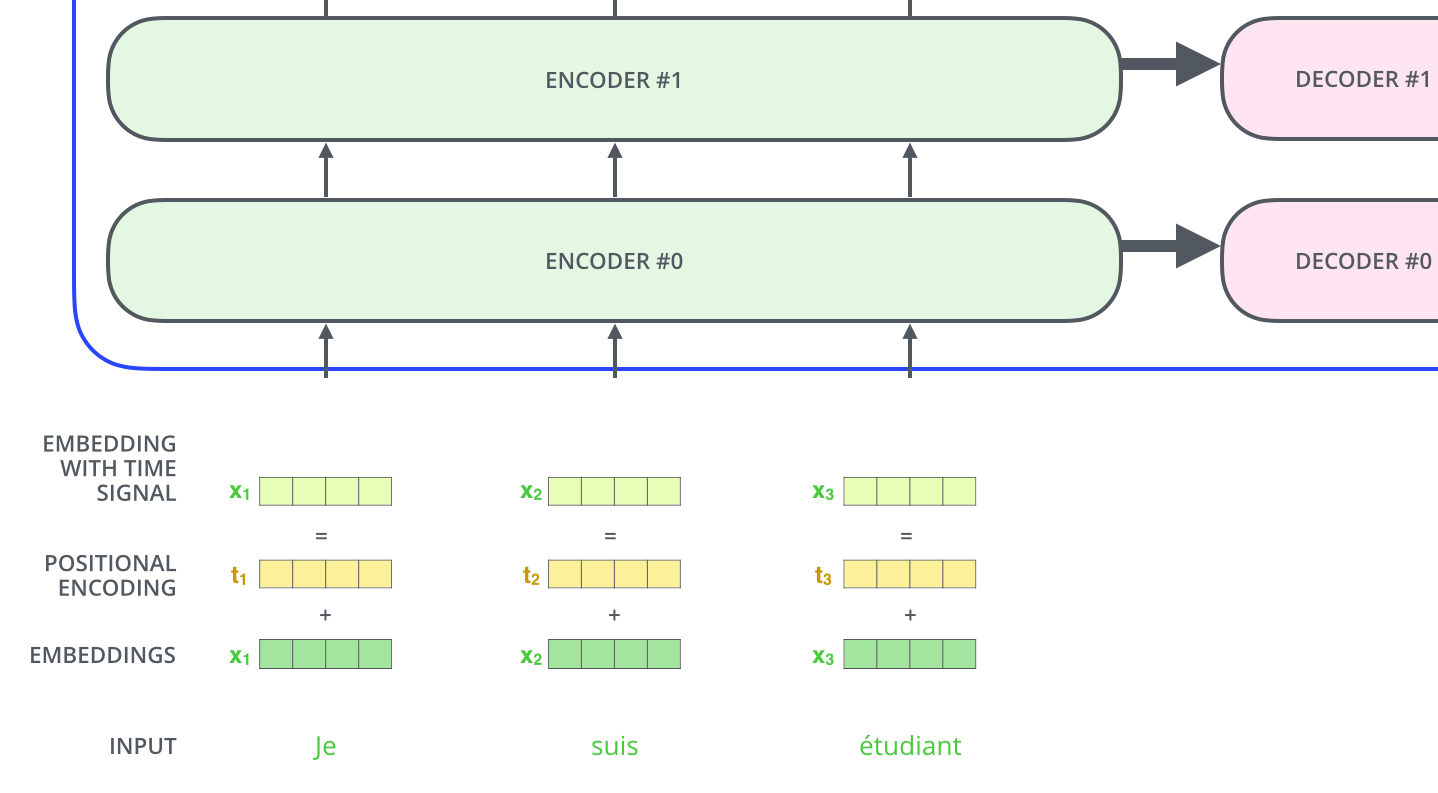
位置编码(Positional Encoding)
Positional Encoding的作用是保留输入序列中词的位置信息,与输入每个词的embedding相互作用后(element wise add),作为第一个encoder sublayers的输入。这里其shape与Input Embedding矩阵一致。
残差(The Residuals)
在add&norm这一步实际上是为了避免梯度退化,采用了ResNet解决办法:output=output+Q;
norm是标准化矫正一次,采用Layer Norm方法,即在output对最后一维计算均值和方差,用output减去均值除以方差+spsilon得值更新为output,然后变量gamma*output+变量beta。
前馈神经网络(Feed Forward NN)
- 对output进行两次卷积,第一次卷积核11,数目为词对应向量的维度。第二次卷积也是11,数目为N。
- 两次卷积后得到的output和matEnc的shape相同,更新matEnc = output,进行上述循环,循环自定义次数,进入Decoder部分。
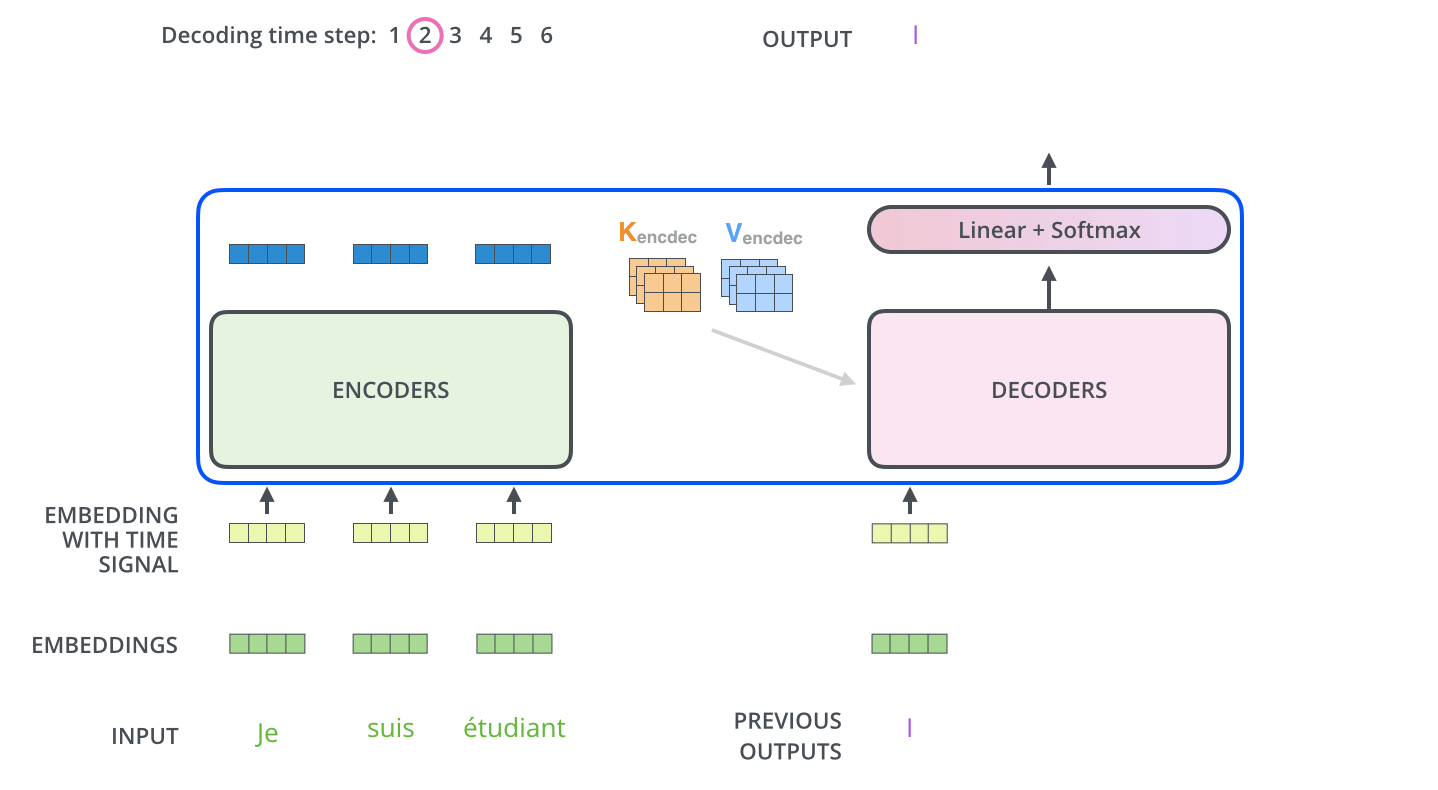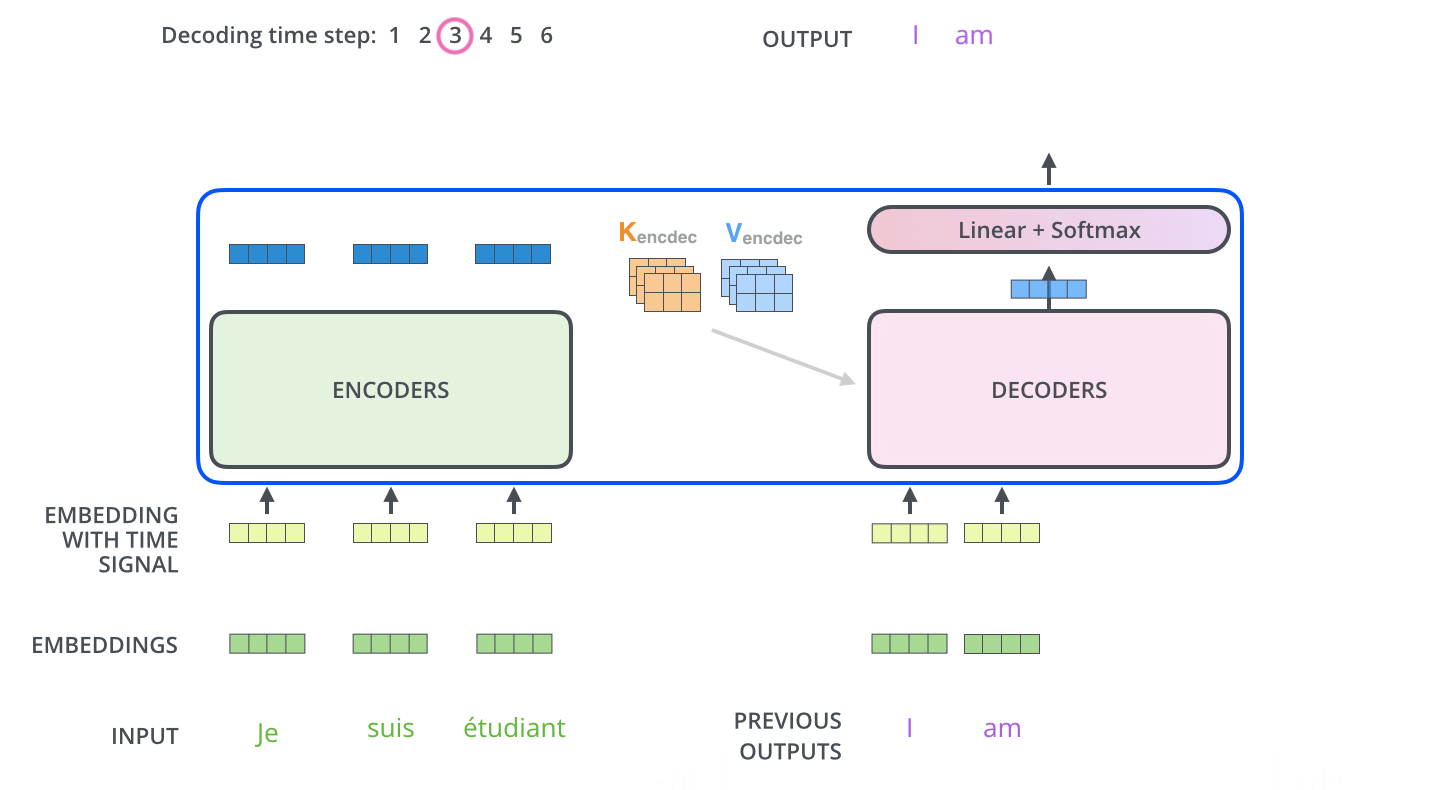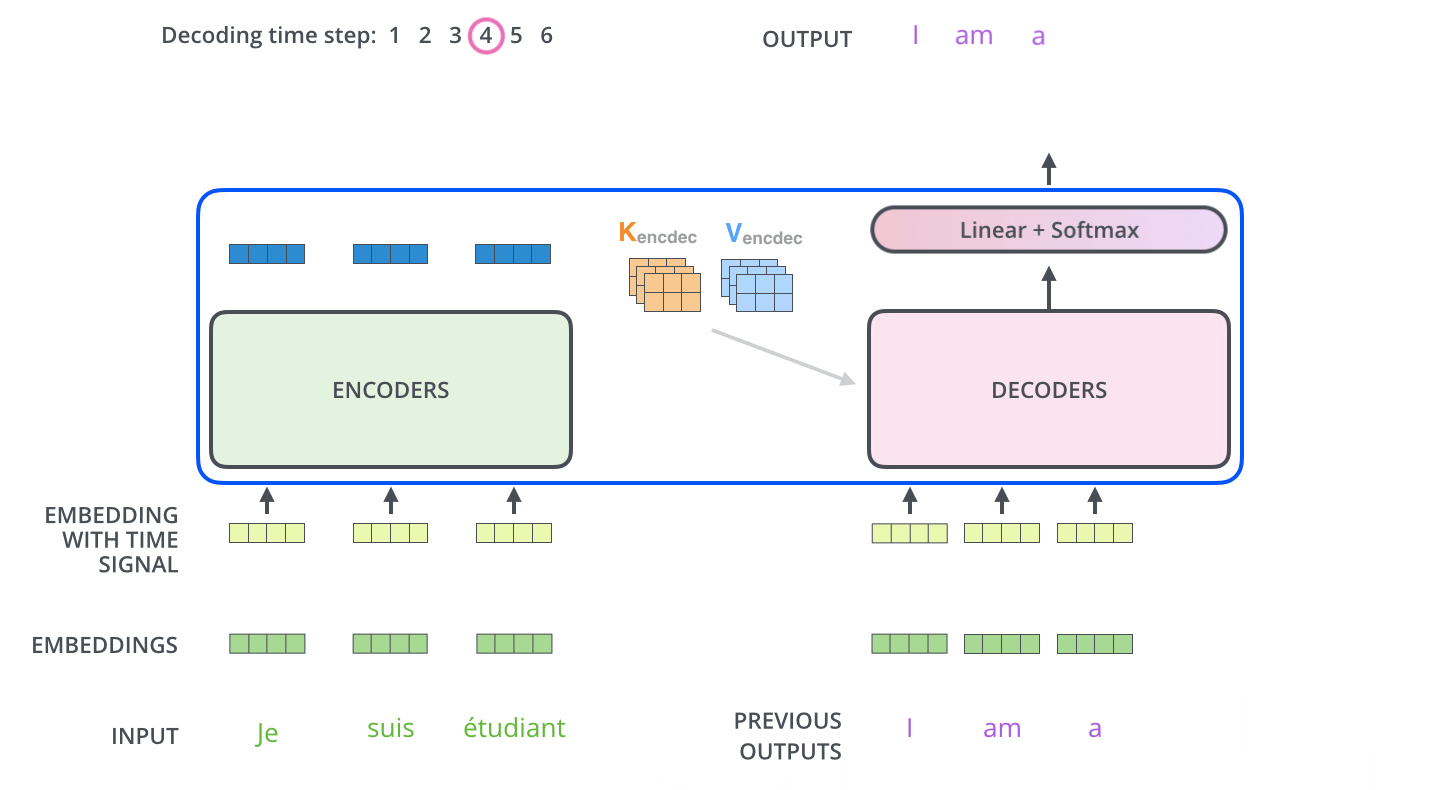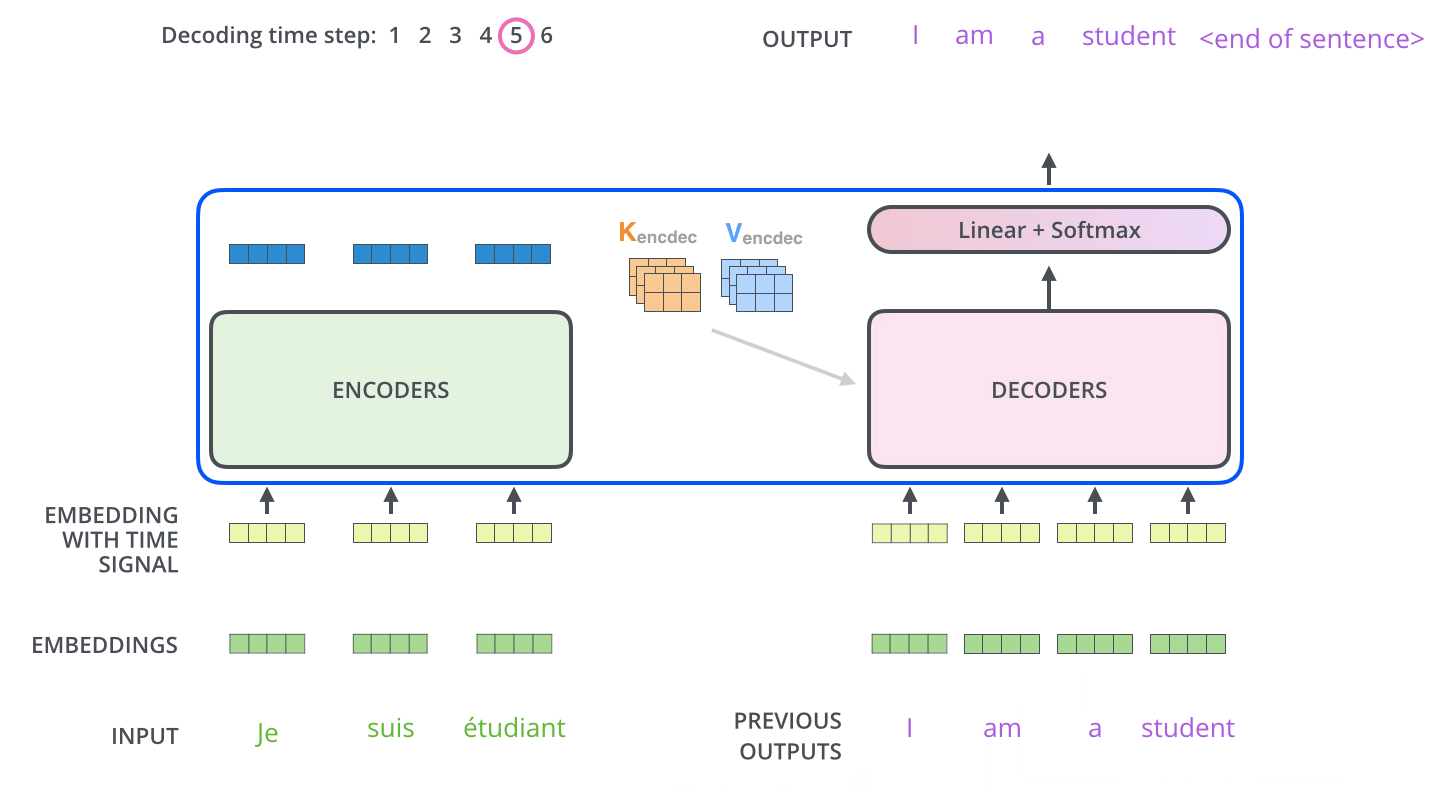
Decoder阶段