第10章:深入浅出ML之Clustering家族
- author: zhouyongsdzh@foxmail.com
- date: 2015-10-15
- weibo: @周永_52ML
内容列表
- 写在前面
- 期望最大值算法
- 高斯混合模型
- K-Means聚类
写在前面
聚类属于无监督学习体系下的一类算法,数据样本通常表示为\(D=\{(x^{(1)}, ?), (x^{(2)}, ?), \cdots, (x^{(m)}, ?)\}\)。与分类相比,最明显的特征就是标签\(y\)未知(这里用\(?\)表示)。
那么如何把相近的样本点聚合在一起,同样不相近的样本尽可能不在同一个簇中?一个思路就是假设每个样本有标签,只是“隐藏”起来了,把它当作隐变量(latent variable)。然后用监督学习的思路去求解,把相同标签的样本聚合在一起即可。
如此一来,会发现整个过程出现两类变量:
- 样本类别变量
- 模型参数变量
传统的参数学习算法无法解决该类问题,How to do it? 下面要介绍的期望最大值算法可以很好的解决该类问题。
期望最大值算法
期望最大值(Expectation Maximization,简称EM算法)是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量。
其主要思想就是通过迭代来建立完整数据的对数似然函数的期望界限,然后最大化不完整数据的对数似然函数。
本节将尽可能详尽地描述EM算法的原理。并结合下一节的高斯混合模型介绍EM算法是如何求解的。
数学铺垫
Jensen不等式
在《最优化》相关的资料中,通常会提到凸函数与凹函数的概念。假设\(f\)是定义域为实数的函数,如果对于所有的实数\(x\),函数的二阶导数\(f^{\prime\prime}(x) \ge 0\)(如果存在的话),那么\(f\)就是凸函数。
当\(x\)是向量时,如果其对应的Hessian矩阵H是半正定的(\(H \ge 0\)),那么\(f\)是凸函数。如果\(f^{\prime\prime}(x) > 0\)或\(H>0\),那么称\(f\)是严格凸函数。
(将\(\ge 0\)换成\(\le 0\)(或者\(>0\)换成\(<0\))得到的是凹函数的概念。)
Jensen不等式表述如下:
如果\(f\)是凸函数,\(X\)是随机变量,那么有 \(E[f(X)] \ge f (E[X])\).
特别的,如果\(f\)是凸函数,那么 \(E[f(X)] = f[E(X)]\)当且仅当\(p(x=E[X])=1\),此时随机变量\(X\)就是常量。
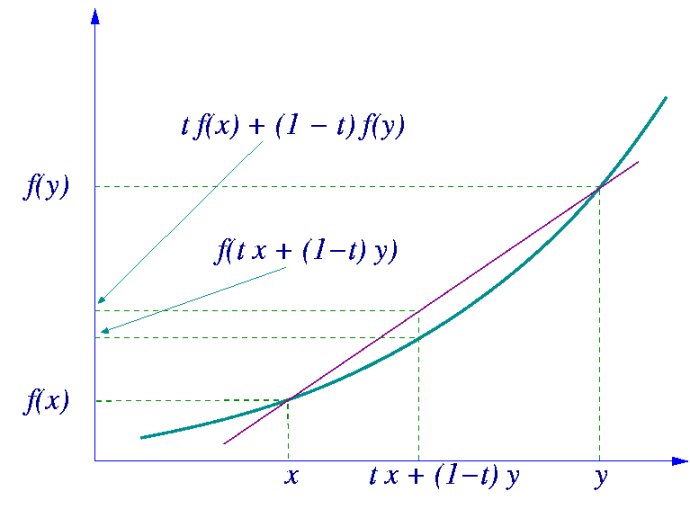
在图中,实现\(f\)是凸函数,\(X\)是随机变量,假设其取值为\(x\)和\(y\)(概率分别为0.5)。那么\(X\)的期望值就是\([x,y]\)的中值,从图中可以看到\(E[f(x)] \ge f(E[x])\)成立。
Jensen不等式同样可应用于凹函数,不等号方向相反即可,即\(E[f(X)] \le f(E[X])\)。
EM算法描述
EM初探
假设给定训练样本\(\{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\}\),且样本间独立。我们想寻找每个样本隐变量(类别\(z\)),使得\(P(x,z)\)最大。\(P(x,z)\)的最大似然估计(取对数)如下:
$$
\ell(w) = \sum_{i=1}^{m} \log P(x^{(i)}; w) = \sum_{i=1}^{m} \log \left( \sum_{z} P(x^{(i)}, z; w) \right) \qquad(ml.1.10.1)
$$解释公式\((ml.1.10.1)\),首先对极大似然函数取对数,然后对每个样本的每一种可能类别\(z\)求联合分布概率之和。
直接求参数\(w\)会比较困难,因为有隐变量\(z\)的存在,如果确定了\(z\)之后,再求解就容易了(不同于监督学习过程,这里存在两个变量:模型参数变量\(w\)和模型类别变量\(z\))。
EM算法是一种求解存在隐变量的参数优化问题的有效方法。既然不能直接最大化\(\ell(w)\),我们可以不断的建立\(\ell\)的下界(E步),然后优化下界(M步)。
公式推导
对于每一个样本\(x^{(i)}\),这里用\(Q_i\)表示该样本隐变量\(z\)的某种分布,\(Q_i\)满足的条件\(\sum_{z} Q_i(z) = 1\)且\(Q_i(z)\ge 0\)。
如果\(z\)是连续型的,那么\(Q_i\)就是概率密度函数,需要将求和符号换成积分符号。比如要将班上学生聚类,假设隐含变量\(z\)表示身高,那么可以认为该变量服从高斯分布。如果隐含变量表示性别,那么\(z\)就服从伯努利分布了。
根据前面的数学铺垫和公式\((ml.1.10.1)\),可得下面的公式:
$$
\begin{align}
\sum_{i=1}^{m} \log P(x^{(i)}; w) & = \sum_{i=1}^{m} \log \left( \sum_{z^{(i)}} P(x^{(i)}, z^{(i)}; w) \right) \qquad\qquad(1)\\
& = \sum_{i=1}^{m} \underline{ \log \left( \sum_{z^{(i)}} Q_i(z^{(i)}) \frac{P(x^{(i)}, z^{(i)}; w)}{Q_i(z^{(i)})}\right) } \;\,\quad(2)\\
& \ge \sum_{i=1}^{m} \underline{\sum_{z^{(i)}} Q_i(z^{(i)}) \log \frac{P(x^{(i)}, z^{(i)}; w)}{Q_i(z^{(i)})} } \;\;\,\qquad(3)
\end{align} \quad(ml.1.10.2)
$$公式\((ml.1.10.2)\)解释:
(1)到(2)比较直接,分子分母同乘以一个相等的函数;(2)到(3)利用了Jensen不等式。这里面函数\(log(x)\)是凹函数(二阶导数小于0),并且
$$
\sum_{z^{(i)}} Q_i(z^{(i)}) \left[\frac{p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right] \qquad(n.ml.1.10.1)
$$就是\(\left[ \frac {p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right]\)的期望。
设\(Y\)是随机变量\(X\)的函数,\(Y=g(X)\)(\(g\)是连续函数),那么有:
①. \(X\)是离散型随机变量,它的分布律为\(P(X=x_k) = p_k\)(\(k=1,2,\cdots\))。若\(\sum_{k=1}^{\infty} g(x_k)p_k\)绝对收敛,则有
$$
E[Y] = E[g(X)] = \sum_{i=1}^{\infty} g(x_k) p_k \qquad(n.ml.1.10.2)
$$②. \(X\)是连续型随机变量,其对应的概率密度为\(f(x)\),若\(\int_{-\infty}^{\infty} g(x) f(x) dx\)绝对收敛,则有
$$
E[Y] = E[g(X)] = \int_{-\infty}^{\infty} g(x) f(x) dx \qquad(n.ml.1.10.3)
$$回到公式\((ml.1.10.2)\),\(Y\)相当于\(\left[ \frac {p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right]\);\(X\)是\(z^{(i)}\);\(Q_i(z^{(i)})\)是\(p_k\); \(g\)是\(z^{(i)}\)到\(\left[ \frac {p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right]\)的映射。
这样就解释了\((2)\)的期望,然后根据Jensen不等式,得到:
$$
f \left(E_{z^{(i)} \sim Q_i} \left[ \frac {p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right] \right) \ge E_{z^{(i)} \sim Q_i} \left[ f\left( \frac {p(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} \right)\right] \quad(n.ml.1.10.4)
$$公式\((ml.1.10.2)-(3)\)可以看作是对对数似然函数\(\ell(w)\)求了下界。对于\(Q_i\)的选择,有很多种可能,那么哪种更好呢?
E步
为了回答上面的问题,我们先假设参数\(w\)已经给定,那么\(\ell(w)\)的值就决定于\(Q_i(z^{(i)})\)和\(P(x^{(i)}, z^{(i)})\)了。这样我们就可以通过调整这两个概率使下界不断上升,以逼近\(\ell(w)\)的真实值。那么,什么时候算是调整好了呢?当公式\((ml.1.10.2)\)不等式变成等式时,说明我们调整后的结果等价于\(\ell(w)\)。
按照上述思路,我们需要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,即:
$$
\frac {P(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} = c \quad(等式成立条件)\quad(ml.1.10.3)
$$这里\(c\)是常数,不依赖\(z^{(i)}\)。对上式进一步推导,我们知道有\(\sum_{z} Q_i(z^{(i)})=1\),那么就有\(\sum_{z} P(x^{(i)}, z^{(i)}; w) = c\)。进而可以得到:
$$
\begin{align}
Q_i(z^{(i)}) & = \frac {P(x^{(i)}, z^{(i)}; w)} {\sum_z P(x^{(i)}, z^{(i)}; w)} = \frac {P(x^{(i)}, z^{(i)}; w)} {P(x^{(i)};w)} \\
& = P(z^{(i)}|x^{(i)};w)
\end{align} \qquad(ml.1.10.4)
$$这里,\(Q_i\)是第\(i\)个样本隐变量\(z\)的某种分布假设。通过建立\(\ell(w)\)的下界,并根据Jensen不等式的等式成立条件,推导出\(Q_i\)对应的计算公式就是后验概率\(P(z|x;w)\)。
到此,我么推出了在固定参数\(w\)后,\(Q_i(z^{(i)})\)的计算公式就是后验概率,解决了\(Q_i(z^{(i)})\)如何选择的问题。这一步称为E步:建立对数似然函数\(\ell(w)\)的下界。
M步
接下来,在给定\(Q_i(z^{(i)})\)后,调整参数\(w\),极大化\(\ell(w)\)的下界(固定\(Q_i\)后,下界还可以调整的更大)。因此,EM算法的步骤可描述如下(伪代码):
\(
\begin{align}
& Loop \; until \; convergence \; \{ \\
& \qquad E-Step: for \; each \; i, \; calculate: \\
& \qquad\qquad\qquad\qquad \underline{ Q_i(z^{(i)}) := P(z^{i}|x^{(i)};w)} \qquad(n.ml.1.10.5)\\
& \qquad M-Step: calculate: \\
& \qquad\qquad\qquad \underline{ w := \arg \max_w \sum_{i=1}^{m} \sum_{z^{(i)}} Q_i(z^{(i)}) \log \frac{P(x^{(i)}, z^{(i)}; w)} {Q_i(z^{(i)})} } \quad(n.ml.1.10.6)\\
& \}
\end{align}
\)伪代码中提到,直到收敛循环才退出。那么如何保证收敛?这是下一节要介绍的内容。
EM算法收敛性证明
假定\(w^{(t)}\)和\(w^{(t+1)}\)是EM算法在第\(t\)次和第\(t+1\)次得到的结果。如果能够证明\(\ell(w^{(t)}) \le \ell(w^{(t+1)})\),即极大似然估计单调递增,那么最终我们会达到最大似然估计的最大值。
收敛性证明
[第\(t\)次:E步]选定 \(w^{(t)}\)后,可以得到E步:
$$
Q_i^{(t)}(z^{(i)}) = P(z^{(i)} | x^{(i)}; w^{(t)}) \qquad(n.ml.1.10.7)
$$这一步保证了再给定\(w^{(t)}\)时,Jensen不等式中的等式成立,也就是
$$
\ell(w^{(t)}) = \sum_{i=1}^{m} \sum_{z^{(i)}} Q_i^{(t)} (z^{(i)}) \cdot \log \frac{P(x^{(i)}, z^{(i)}; w^{(t)})} {Q_i^{(t)} (z^{(i)})} \qquad(n.ml.1.10.8)
$$[第\(t\)次:M步]然后进行M步,固定\(Q_i^{(t)}(z^{(i)}) \),并将\(w^{(t)}\)视为变量,对上面的\(\ell(w^{(t)})\)求导后,得到\(w^{(t+1)}\)。经过一些推导,整理后会得到如下式子:
$$
\begin{align}
\ell(w^{(t+1)}) & \ge \sum_{i=1}^{m} \sum_{z^{(i)}} Q_i^{(t)} (x^{(i)}) \cdot \log \frac{P(x^{(i)}, z^{(i)}; w^{(t+1)})} {Q_i^{(t)} (x^{(i)})} \quad(1)\\
& \ge \sum_{i=1}^{m} \sum_{z^{(i)}} Q_i^{(t)} (x^{(i)}) \cdot \log \frac{P(x^{(i)}, z^{(i)}; w^{(t)})} {Q_i^{(t)} (x^{(i)})} \;\;\,\quad(2)\\
& = \ell(w^{(t)})
\end{align} \qquad(n.ml.1.10.9)
$$公式\((n.ml.1.10.9)\)的\((1)\),得到\(w^{(t+1)}\)时,只是最大化了\(\ell(w^{(t)})\),也就是\(\ell(w^{(t+1)})\)的下界,而没有使等式成立。(在第\(t+1\)次的E步时等式才成立,即固定\(w^{(t+1)}\),并按照Jensen不等式得到\(Q_i\)时。)
第\((1)\)步的成立可以根据公式\((ml.1.10.2)\)来论证。这里的第\((2)\)步直接利用了M步的定义,M步就是将\(w^{(t)}\)调整为\(w^{(t+1)}\),使得下界最大化。
| EM算法思想总结: |
|---|
| E步会将下界拉到与\(\ell(w)\)一个特定值(这里是\(w^{(t)}\))一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升;但达不到与\(\ell(w)\)另外一个特定值(这里是\(w^{(t+1)}\))一样的高度,然后又进行E步…,如此重复下去,直到最大值。 |
这样我们就证明了\(\ell(w)\)会单调增加。收敛方式可以用两种:一种是\(\ell(w)\)不再变化,另一种是\(\ell(w)\)变化幅度很小。
为了更好的理解EM与其它优化算法的关系,下面我们定义一个公式:
$$
J(Q,w) = \sum_{i=1}^{m} \sum_{z^{(i)}} Q_i^{(t)} (z^{(i)}) \cdot \log \frac{P(x^{(i)}, z^{(i)}; w^{(t)})} {Q_i^{(t)} (z^{(i)})} \qquad(ml.1.10.5)
$$
从前面的推导中我们知道了\(\ell(w) \ge J(Q,w)\),那么EM算法可以看作是函数\(J\)的坐标上升法:E步固定w,优化Q;M步固定Q,优化w。
高斯混合模型
密度估计(Density Estimation)是无监督学习非常重要的一个应用方向。本节主要介绍高斯混合模型(Gaussian Mixture Model,简称GMM)如何求解,进而做密度估计的?。
GMM介绍
假设给定训练样本\(\{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\}\),且样本间独立,将隐含类别标签用\(z^{(i)}\)表示(即EM中的隐变量)。我们首先认为\(z^{(i)}\)是满足一定概率分布的(不是绝对的一个固定值),这里假设满足多项式分布:\(z^{(i)} \sim Miltinomial(\phi)\),其中\(P(z^{(i)} = j) = \phi_j, \phi_j \ge 0, \sum_{j=1}^{k} \phi_j = 1,z^{(j)}\)有\(k\)个值\(\{1,2,\cdots,k\}\)可选。
并且我们认为在给定\(z^{(i)}\)后,\(x^{(i)}\)满足多变量高斯分布,即\(x^{(i)}|z^{(i)}=j \sim N(\mu_j, \Sigma)\)。由此可以得到联合分布\(P(x^{(i)}, z^{(i)}) = P(x^{(i)}|z^{(i)}) \cdot P(z^{(i)})\)。
多变量高斯分布介绍可参考《深入浅出ML》系列第05章高斯判别分析模型部分。
高斯混合模型可以描述为:
对每个样本\(x^{(i)}\),我们先从\(k\)个类别中按照多项式分布抽取一个\(z^{(i)}\),然后根据\(z^{(i)}\)所对应的_\(k\)个多变量高斯分布中的一个_生成样本\(x^{(i)}\)。整个建模过程得到的模型称为高斯混合模型。
需要注意的是,这里的\(z^{(i)}\)仍然是隐随机变量(不同于高斯判别分析中的类别已知,监督学习)。模型中还有三个变量\(\phi, \mu\)和\(\Sigma\)。最大似然估计为联合概率分布\(P(x,z)\),取对数后:
$$
\begin{align}
\ell(\phi, \mu, \Sigma) & = \sum_{i=1}^{m} \log \underline{ P(x^{(i)}; \phi, \mu, \Sigma) } \\
& = \sum_{i=1}^{m} \log \underline{ \left(\sum_{z^{(i)}=1}^{k} P(x^{(i)}|z^{(i)}; \mu, \Sigma) \cdot P(z^{(i)}; \phi)\right)}
\end{align} \qquad(ml.1.10.6)
$$\(x^{(i)}\)是观测值,已经存在的。那么它是如何生成的呢?是以最大概率生成的… (MLE的思想)。
公式\((ml.1.10.6)\)的最大值不能通过高斯判别分析中直接求参数偏导并置为0的方法解决。但是我们假设已经知道了每个样本的标签\(z^{(i)}\),那么公式\((ml.1.10.6)\)可以简化为:
$$
\ell(\phi, \mu, \Sigma) = \sum_{i=1}^{m} \left( \log P(x^{(i)}|z^{(i)}; \mu, \Sigma) + \log P(z^{(i)}; \phi) \right) \qquad(ml.1.10.7)
$$此时,我们再对\(\phi, \mu\)和\(\Sigma\)求导,可得:
$$
\begin{align}
\phi_j & = \frac{1}{m} \sum_{i=1}^{m} 1\{z^{(i)}=j\} \qquad\qquad(1)\\
\mu_j & = \frac{\sum_{i=1}^{m} 1\{z^{(i)}=j\}x^{(i)}} {\sum_{i=1}^{m} 1\{z^{(i)}=j\}} \quad\qquad(2) \\
\Sigma_j & = \frac {\sum_{i=1}^{m} 1\{z^{(i)}=j\} \cdot (x^{(i)} -\mu_j) (x^{(i)} -\mu_j)^T} {\sum_{i=1}^{m} 1\{z^{(i)}=j\}} \quad(3)
\end{align} \qquad(ml.1.10.8)
$$\(\phi_j\)就是样本类别中\(z^{(i)}=j\)的占比。\(\mu_j\)是类别为\(j\)的样本特征均值,\(\Sigma_j\)是类别为\(j\)的样本的特征对应的协方差矩阵。
公式\((2)\)中的\(\mu_j\)是一个\(n\)维向量:类标号为\(j\)的样本的特征累加和对应的均值。因此\(\mu = (\mu_1, \mu_2, \cdots, \mu_k)^T\)是一个\(k_n\)的矩阵。\(\Sigma_j\)是一个\(n_n\)的方阵,所有类标号为\(j\)的样本(特征集合)都服从相同参数\((\mu_j, \Sigma_j)\)的多变量高斯分布。
高斯混合模型与高斯判别分析
实际上,当知道样本的隐含变量\(z^{(i)}\)(类标号)后,极大似然估计就等同于高斯判别分析模型了。从表面上看,二者不同的是GDA中的类别\(y\)服从伯努利分布,而这里的\(z\)服从多项式分布;此外,这里的每个样本都有不同的协方差矩阵,而GDA中只有一个。
公式\((ml.1.10.6)\)与第5章中的\((ml.1.5.6)\)表达的是同一个意思。包括\((ml.1.10.8)与(ml.1.5.7)\)的求解结果,在物理意义也是等价的。
| GMM与GDA相同点: |
|---|
| 1. 模型的概率假设相同:类别\(z^{(i)}\)服从多项式分布,样本特征服从多变量高斯分布; |
| 2. 目标函数一致:都是联合概率分布(在训练集上)的极大似然估计 |
| GMM与GDA不同点: |
|---|
| 1. 学习方式不同:GDA是有监督学习,而GMM用于无监督学习; |
| 2. 求解算法不同:GDA直接通过MLE求参数偏导即可得到闭式解;GMM因为有隐变量,需要用EM算法不断迭代,得到结果。 |
GMM参数学习过程
公式\((ml.1.10.7)\)假设给定了\(z^{(i)}\),而实际上\(z^{(i)}\)是不知道的,那怎么求解参数呢?
回到EM算法思想:用E步猜测隐含变量\(z^{(i)}\)的分布;用M步更新其它参数,以获得更大的似然函数估计值。
因此用EM算法求解高斯混合模型的步骤如下(伪代码):
\(
\begin{align}
& Loop \; until \; convergence \; \{ \\
& \qquad E-Step: for \; each \; i \; and \; j, \; calculate: \\
& \qquad\qquad\qquad\qquad w_j^{(i)} := P(z^{(i)}=j|x^{(i)}; \phi, \mu, \Sigma) \\
& \qquad M-Step: \; update \; parameters: \\
& \qquad\qquad\qquad\qquad \phi_j : = \frac{1}{m} \sum_{i=1}^{m} w_j^{(i)} \\
& \qquad\qquad\qquad\qquad \mu_j := \frac {\sum_{i=1}^{m} w_j^{(i)} x^{(i)}} {\sum_{i=1}^{m} w_j^{(i)}} \\
& \qquad\qquad\qquad\qquad \Sigma_j := \frac {\sum_{i=1}^{m} w_j^{(i)} \cdot (x^{(i)} -\mu_j) (x^{(i)} -\mu_j)^T} {\sum_{i=1}^{m} w_j^{(i)}}\\
& \}
\end{align}
\)这里,在E步中,我们将其它参数\(\phi, \mu, \Sigma\)看作常量,计算\(z^{(i)}\)的后验概率,也就是估计隐变量,即为观测样本”划分”类标号,更新每一个样本\(i\)可能的每一个类标号\(j\)的概率分布。
M步是最大似然估计,通过更新参数实现。这里根据估计出来的属于每一个类的样本,重新计算属于这个类的参数。计算好后发现最大化似然估计时,\(w_j^{(i)}\)值又不对了,需要重新计算,如此循环,直至收敛。
参数\(w_j^{(i)}\)的计算公式如下:
$$
P(z^{(i)}=j|x^{(i)}; \phi, \mu, \Sigma) = \frac {P(x^{(i)}|z^{(i)}=j; \mu, \Sigma) \cdot P(z^{(i)}=j; \phi)} {\sum_{l=1}^{k} P(x^{(i)}|z^{(i)}=l; \mu, \Sigma) \cdot P(z^{(i)}=l; \phi)} \quad(ml.1.10.9)
$$\((ml.1.10.9)\)利用了贝叶斯公式。之所以是条件概率,是因为该式由Jensen不等式推导而来,通过建立似然函数的下界。
在伪代码中使用了\(w_j^{(i)}\)代替了公式\((ml.1.10.8)\)中的\(1\{z^{(i)}=j\}\),由0/1值变成了概率值。
跟下面要介绍的经典聚类算法K-menas相比,这里使用类别“软”指定,为每个样例分配的类别\(z^{(i)}\)是有概率分布的,同时计算量也变大了,每个样例\(i\)都要计算属于每一个类别\(j\)的概率。与K-means相同的是,结果仍然是局部最优解。对其它参数取不同的初始值进行多次计算不失为一种好方法。
K-means聚类
K-menas是聚类算法中最经典的一个。这里首先介绍K-means算法的流程,然后阐述其背后包含的EM思想。
关于聚类
聚类属于无监督学习,之前章节中的Regression,Naive Bayes,SVM等都是有类别标签的,也就是样本中已经给出了真实分类标签。而聚类样本中没有给定标签,只有特征(向量)。
比如假设宇宙中的星星可以表示成三维空间中的点集\((x_1,x_2,x_3)\)。聚类的目的就是找个到每个样本\(\vec{x}\)潜在的类别\(y\),并将同类别\(y\)的样本\(\vec{x}\)放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,训练样本是\(x^{(1)}, x^{(2)}, \cdots, x^{(m)}\),每个\(x^{(i)} \in R^n\),没有类别\(y^{(i)}\)。
K-means算法流程
K-means算法是将样本聚类成k个簇,算法描述如下:
\(\{ \\
\qquad\, Step1: 随机选区k个聚类质心点(cluster centroids),为\mu_1, \mu_2, \cdots, \mu_k \in R^n. \\
\qquad Step2: Loop \; Until \; Convergence \{ \\
\qquad\qquad 对于每一个样例i,计算其应该属于的类。计算公式 \\
\qquad\qquad\qquad c^{(i)} := \arg \min_j |x^{(i)} - \mu_j|^2 \\
\qquad\qquad 对于每一个类j,重新计算该类的质心 \\
\qquad\qquad\qquad \mu_j := \frac{\sum_{i=1}^{m} 1\{c^{(i)}=j\}x^{(i)}} {\sum_{i=1}^{m} 1\{c^{(i)}=j\}} \\
\qquad \} \\
\}
\)\(Step1\)中的k是事先给定的聚类数,\(c^{(i)}\)代表样例\(i\)和\(k\)个类中距离较近的那个类。
\(c^{(i)}\)的值为\({1,2,\cdots,k}\)。质心\(\mu_j\)表示我们对属于同一个类的样本中心点的猜测。以星团模型为例,就是要将所有的星星聚成\(k\)个星团,首先随机选取\(k\)个宇宙中的点(即\(k\)个星星)作为\(k\)个星团的质心。代码示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#include<iostream>
#include<cmath>
#include<vector>
#include<ctime>
using namespace std;
typedef unsigned int uint;
struct Cluster
{
vector<double> centroid;
vector<int> samples;
}
vector<Cluster> k_means(vector<vector<double> > trainX, int k, int maxepoches)
{
const int row_num = trainX.size();
const int col_num = trainX[0].size();
/*初始化聚类中心*/
vector<Cluster> clusters(k);
int seed = (int)time(NULL);
for (int i = 0; i < k; i++)
{
srand(seed);
int c = rand() % row_num;
clusters[i].centroid = trainX[c];
seed = rand();
}
......
}
+ 然后,迭代中的每一步计算每个星星到k个质心中的每一个的距离,选取距离最近的那个星团作为\\(c^{(i)}\\)。
这样经过第一步每个星星都有了所属的星团;第二步对于每个星团,重新计算它的质心\\(\mu_j\\)(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直至质心不变或变动很小。示例代码如下:vector
k_means(vector
{const size_t row_num = trainX.size(); const size_t col_num = trainX[0].size(); /*初始化聚类中心*/ (在此省略) /*多次迭代直至收敛,这里固定迭代次数(100次)*/ for (int it = 0; it < maxepoches; it++) { /*每一次重新计算样本点所属类别之前,清空原来样本点信息*/ for (int i = 0; i < k; i++) { clusters[i].samples.clear(); } /*求出每个样本点距应该属于哪一个聚类*/ for (int j = 0; j < row_num; j++) { /*都初始化属于第0个聚类*/ int c = 0; double min_distance = cal_distance(trainX[j], clusters[c].centroid); for (int i = 1; i < k; i++) { double distance = cal_distance(trainX[j], clusters[i].centroid); if (distance < min_distance) { min_distance = distance; c = i; } } clusters[c].samples.push_back(j); } /*更新聚类中心*/ for (int i = 0; i < k; i++) { vector<double> val(col_num, 0.0); for (int j = 0; j < clusters[i].samples.size(); j++) { int sample = clusters[i].samples[j]; for (int d = 0; d < col_num; d++) { val[d] += trainX[sample][d]; if (j == clusters[i].samples.size() - 1) { clusters[i].centroid[d] = val[d] / clusters[i].samples.size(); } } } } } // 多次迭代,直至收敛 return clusters;}
double cal_distance(vector
a, vector b)
{size_t da = a.size(); size_t db = b.size(); if (da != db) { cerr << "Dimensions of two vectors must be same!\n"; } double val = 0.0; for (size_t i = 0; i < da; i++) { val += pow((a[i] - b[i]), 2); } return pow(val, 0.5);}
K-means收敛性
k-means面对的第一个问题是如何保证收敛,算法描述中抢到结束条件就是收敛,可以证明的是k-means完全可以保证收敛。下面是定性的描述,先定义畸变函数(Distortion Function)如下:
$$
J(c,\mu) = \sum_{i=1}^{m} |x^{(i)} - \mu_{c^{(i)}}|^2 \qquad(ml.1.10.10)
$$\(J\)函数表示每个样本点到其质心\(\mu\)的距离平方和。k-means的任务是将\(J\)调整到最小。
假设当前\(J\)没有达到最小值,此时可以先固定每个类的质心\(\mu_j\),调整每个样例所属的类别\(c^{(i)}\)来让\(J\)函数减小;同样的,固定\(c^{(i)}\),调整每个类的质心\(\mu_j\)也可以使\(J\)减小。这两个过程就是内循环中使\(J\)单调递减的过程。当\(J\)递减到最小时,\(\mu\)和\(c\)也同时收敛。(理论上,可以存在多组不同的\(\mu\)和\(c\)值能够使得\(J\)取得最小值,但这种情况比较少见)。
由于畸变函数\(J\)是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是k-menas对质心初始位置的选取比较敏感(其实在多数情况下k-means达到的局部最优已经满足需求,如果担心陷入局部最优,可以选区不同的初始值跑多遍k-means,然后去骑中最小的\(J\)对应的\(\mu\)和\(c\)输出)。
K-means与EM算法
这里主要是想阐述清楚k-means和EM之间的关系。首先回到初始问题:我们的目标是将样本划分为\(k\)个类。其实说白了就是求每个样本\(x^{(i)}\)的隐含类别\(y^{(i)}\),然后利用隐含类别\(y^{(i)}\)(有k个取值)将\(x^{(i)}\)归类。
由于我们事先不知道类别\(y^{(i)}\),那就先对每个样本假定一个\(y^{(i)}\)吧。此时新的问题来了:怎么知道假定的对不对?如何评价假定的好不好?我们可以使用极大似然估计来度量,这里就是\(x\)和\(y\)的联合分布\(P(x,y)\)。
如果我们找到的\(y\)能够使\(P(x,y)\)最大,那么可以说\(y\)是样本\(x\)的最佳类别了,\(x\)归类为\(y\)就顺理成章了。但是我们第一次指定的\(y\)不一定会让\(P(x,y)\)最大。而且\(P(x,y)\)还依赖于其它未知参数,当然在给定\(y\)的情况下,我们可以调整其它参数让\(P(x,y)\)最大。但是调整参数后,我们发现有更好的\(y\)可以指定。那么我们重新指定\(y\),然后再计算\(P(x,y)\)最大时的参数,反复迭代知道没有更好的\(y\)可以指定。
联合概率分布\(P(x,y)\)最大所对应的\(y\)就是\(x\)的最佳类别。
更多信息请关注:计算广告与机器学习-CAML 技术共享平台