第03章:深入浅出ML之Tree-Based家族
- author: zhouyongsdzh@foxmail.com
- date: 2015-09-15
- sina weibo: @周永_52ML
内容列表
- 写在前面
- 决策树学习过程
- 特征选择方法
- 决策树解读
- 分类与回归树
- 随机森林
写在前面
本章我想以一个例子作为直观引入,来介绍决策树的结构、学习过程以及具体方法在学习过程中的差异。(注:构造下面的成绩示例数据,来说明决策树的构造过程)
假设某次学生的考试成绩,第一列表示学生编号,第2列表示成绩,第3、4列分别划分两个不同的等级。数据如下表所示:
编号 Score 等级1 等级2 1 82 良好 过关 2 74 中等 不过关 3 68 中等 不过关 4 91 优秀 过关 5 88 良好 过关 6 53 较差 不过关 7 76 良好 过关 8 62 中等 不过关 9 58 较差 不过关 10 97 优秀 过关 定义划分等级的标准:
“等级1”把数据划分为4个区间:
分数区间 [90, 100] [75, 90) [60, 75) [0, 60) 等级1 优秀 良好 中等 较差 “等级2”的划分 假设这次考试,成绩超过75分算过关;小于75分不过关。得到划分标准如下:
分数区间 \(score \ge 75\) \(0 \le score \lt 75\) 等级2 过关 不过关
我们按照树结构展示出来,如下图所示:
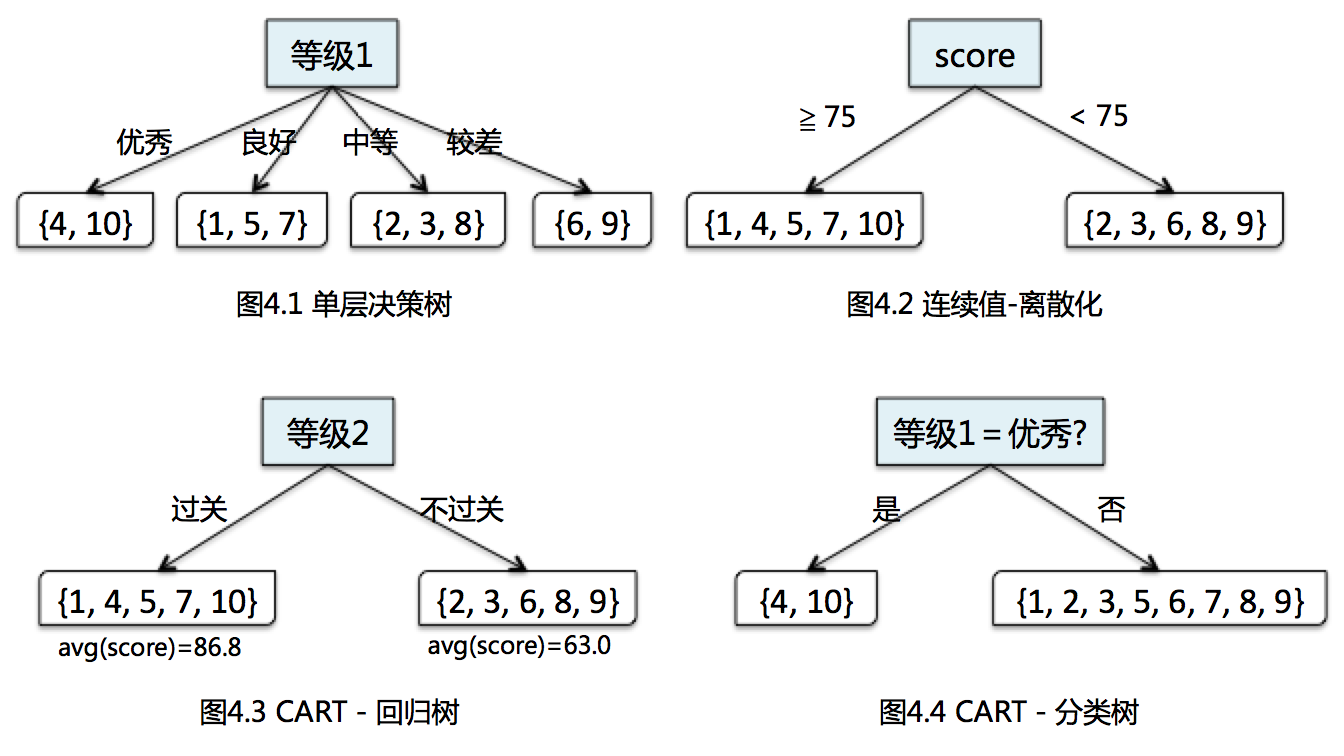
如果按照“等级1”作为划分标准,取值为“优秀”,“良好”,“中等”和“较差”分别对应4个分支,如图4.1所示。由于只有一个划分特征,它对应的是一个单层决策树,亦称作“决策树桩”(Decision Stump)。
决策树桩的特点是:只有一个非叶节点,或者说它的根节点等于内部节点(我们在下面介绍决策树多层结构时再介绍)。
“等级1”取值类型是category,而在实际数据中,一些特征取值可能是连续值(如这里的score特征)。如果用决策树模型解决一些回归或分类问题的话,在学习的过程中就需要有将连续值转化为离散值的方法在里面,在特征工程中称为特征离散化。
在图4.2中,我们把连续值划分为两个区域,分别是\(score \ge 75\) 和 \(0 \le score \lt 75\)
图4.3和图4.4属于CART(Classification and Regression Tree,分类与回归树)模型。CART假设决策树是二叉树,根节点和内部节点的特征取值为”是”或”否”,节点的左分支对应”是”,右分支对应“否”,每一次划分特征选择都会把当前特征对应的样本子集划分到两个区域。
在CART学习过程中,不论特征原有取值是连续值(如图4.2)或离散值(图4.3,图4.4),也要转化为离散二值形式。
直观上看,回归树与分类树的区别取决于实际的应用场景(回归问题还是分类问题)以及对应的“Label”取值类型。
Label是连续值,通常对应的是回归树;当Label是category时,对应分类树模型;
后面会提到,CART学习的过程中最核心的是通过遍历选择最优划分特征及对应的特征值。那么二者的区别也体现在具体的最优划分特征的方法上。
同样,为了直观了解本章要介绍的内容,这里用下述表格来说明:
| 决策树算法 | 特征选择方法 | 作者信息 |
|---|---|---|
| ID3 | 信息增益 | Quinlan. 1986. (Iterative Dichotomiser 迭代二分器) |
| C4.5 | 增益率 | Quinlan. 1993. |
| CART | 回归树: 最小二乘 分类树: 基尼指数 |
Breiman. 1984. (Classification and Regression Tree 分类与回归树) |
除了介绍这3个具体算法对应的特征选择方法外,还会简要地介绍决策树学习过程出现的模型以及数据问题,如过拟合问题,连续值和缺失值问题等。
决策树学习过程
图4.1~图4.4给出的仅仅是单层决策树,只有一个非叶节点(对应一个特征)。那么对于含有多个特征的分类问题来说,决策树的学习过程通常是_一个通过递归选择最优划分特征,并根据该特征的取值情况对训练数据进行分割,使得切割后对应的**_数据子集有一个较好的分类_**的过程_。
为了更直观的解释决策树的学习过程,这里参考《数据挖掘-实用机器学习技术》一书中P69页提供的天气数据,根据天气情况决定是否出去玩,数据信息如下:
ID 阴晴 温度 湿度 刮风 玩 1 sunny hot high false 否 2 sunny hot high true 否 3 overcast hot high false 是 4 rainy mild high false 是 5 rainy cool normal false 是 6 rainy cool normal true 否 7 overcast cool normal true 是 8 sunny mild high false 否 9 sunny cool normal false 是 10 rainy mild normal false 是 11 sunny mild normal true 是 12 overcast mild high true 是 13 overcast hot normal false 是 14 rainy mild high true 否
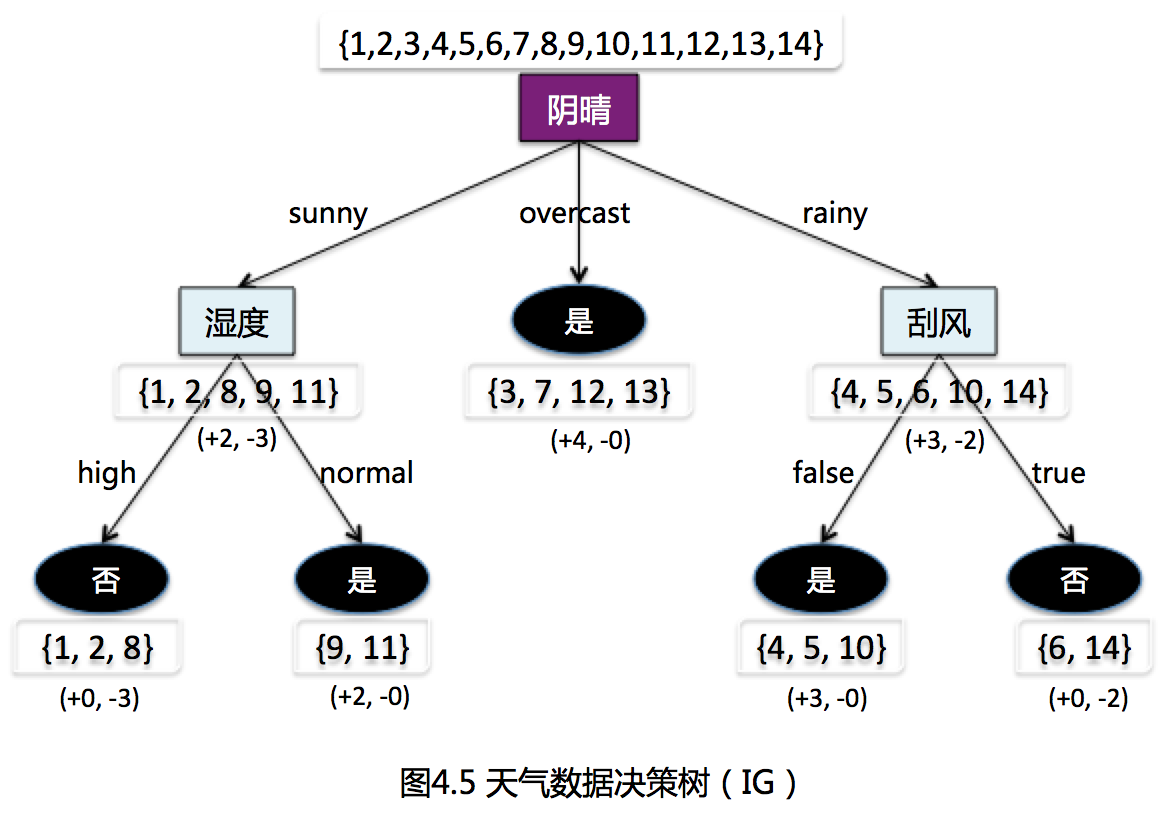
利用ID3算法中的信息增益特征选择方法,递归的学习一棵决策树,得到树结构,如图4.5所示:
假设 训练数据集\(D=\{(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), \cdots, (x^{(m)},y^{(m)}) \} \) (特征用离散值表示),候选特征集合\(F=\{f^1, f^2, \cdots, f^n\} \)。开始,建立根节点,将所有训练数据都置于根节点(\(m\)条样本)。从特征集合\(F\)中选择一个最优特征\(f^{\ast}\),按照\(f^{\ast}\)取值将训练数据集切分成若干子集,使得各个数据子集有一个在当前条件下最好的分类。
如果子集中样本类别基本相同,那么构建叶节点,并将数据子集划分给对应的叶节点;如果子集中样本类别差异较大,不能被基本正确分类,需要在剩下的特征集合(\(F-\{f^{\ast}\}\))中选择新的最优特征,构建相应的内部节点,继续对数据子集进行切分。如此递归地进行下去,直至所有数据子集都能被基本正确分类,或者没有合适的最优特征为止。
这样,最终结果是每个子集都被分到叶节点上,对应着一个明确的类别。那么,递归生成的层级结构即为一棵决策树。我们将上面的文字描述用伪代码形式表达出来,如下:
\(
\{ \\
\quad输入: 训练数据集D=\{(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), \cdots, (x^{(m)},y^{(m)}) \} \; (特征用离散值表示); \\
\qquad\quad\; 候选特征集F=\{f^1, f^2, \cdots, f^n\} \\
\quad输出:一颗决策树T(D,F) \\
\quad学习过程:\\
\qquad 01. \;\; 创建节点node; \\
\quad\;\;\;02. \;\; if \; D中样本全属于同一类别C; \; then \\
\qquad 03. \qquad 将node作为叶节点,用类别C标记,返回; \\
\qquad 04. \; endif \\
\qquad 05. \;\; if \; F为空(F=\emptyset)or \; D中样本在F的取值相同;\; then \\
\qquad 06. \qquad 将node作为叶节点,其类别标记为D中样本数最多的类(多数表决),返回; \\
\qquad 07. \;\underline{ 选择F中最优特征,得到f^{\ast}(f^{\ast} \in F) }; \\
\qquad 08. \;标记节点node为f^{\ast} \\
\qquad 09. \;\; for \; f^{\ast} \;中的每一个已知值f_{i}^{\ast}; \; do \\
\qquad 10. \quad\;\; 为节点node生成一个分支;令D_i表示D中在特征f^{\ast}上取值为f_i^{\ast}的样本子集; \; //划分子集 \\
\qquad 11. \quad\;\; if \; D_i为空;\; then \\
\qquad 12. \qquad\quad 将分支节点标记为叶节点,其类别标记为D_i中样本最多的类;\; then \\
\qquad 13. \quad\;\; else \\
\qquad 14. \qquad\quad 以T(D_i, F-\{f^{\ast}\})为分支节点;\quad // 递归过程 \\
\qquad 15. \quad\;\; endif \\
\qquad 16. \; done
\\\}
\)
决策树学习过程中递归的每一步,在选择最优特征后,根据特征取值切割当前节点的数据集,得到若干数据子集。由于决策树学习过程是递归地选择最优特征,因此可以理解为这是一个特征空间划分的过程。每一个特征子空间对应决策树中的一个叶子节点,特征子空间相应的类别就是叶子节点对应数据子集中样本数最多的类别。
决策树学习过程可以简要的概括为:通过递归地选择最优特征,实现在整个特征空间维度对样本的划分(每个空间对应一个类别),进而完成了整个分类过程。
特征选择方法
上面多次提到递归地选择最优特征,根据特征取值切割数据集,使得对应的数据子集有一个较好的分类。从伪代码中也可以看出,在决策树学习过程中,最重要的是第07行,即如何选择最优特征?也就是我们常说的特征选择问题。
顾名思义,特征选择就是将特征的重要程度进行量化后,得到的结果再进行选择,而如何量化特征的重要性,就成了各种方法间最大的区别。
例如卡方检验、斯皮尔曼法(Spearman)、互信息等使用
<feature, label>之间的关联性来进行量化feature的重要程度。关联性越强,特征得分越高,该特征越应该被优先选择。
决策树中,我们希望随着特征选择过程地不断进行,决策树的分支节点所包含的样本尽可能属于
同一类别,即希望节点的”纯度(purity)”越来越高。
如果子集中的样本都属于同一个类别,当然是最好的结果;如果说大多数的样本类型相同,只有少部分样本不同,也可以接受。
那么如何才能做到选择的特征对应的样本子集纯度最高呢?
ID3算法用信息增益来刻画样例集的纯度; C4.5算法采用增益率; CART算法采用基尼指数来刻画样例集纯度。
信息增益
信息增益(Information Gain,简称IG)衡量特征的重要性是根据当前特征为划分带来多少信息量,带来的信息越多,该特征就越重要,此时节点的”纯度”也就越高。
分类系统的信息熵,我们在第02章:熵与信息熵部分已经给出计算公式,这里再复习一下:
对一个分类系统来说,假设类别\(C\)可能的取值为\(c_1, c_2, \cdots, c_k\)(\(k\)是类别总数),每一个类别出现的概率分别是\(p(c_1),p(c_2), \cdots, p(c_k)\)。此时,分类系统的熵可以表示为:
$$
H(C ) = - \sum_{i=1}^{k} p(c_i) \cdot \log_{2} p(c_i) \qquad (n.ml.1.3.1)
$$分类系统的作用就是输出一个特征向量(文本特征、ID特征、特征特征等)属于哪个类别的值,而这个值可能是\(c_1, c_2, \cdots, c_k\),因此这个值所携带的信息量就是公式\((n.ml.1.3.1)\)这么多。
假设离散特征\(t\)的取值有\(I\)个,\(H(C|t=t_i)\) 表示特征\(t\)被取值为\(t_i\)时的条件熵;\(H(C|t)\)是指特征\(t\)被固定时的条件熵。二者之间的关系是:
$$
\begin{align}
H(C|t) & = p_1 \cdot H(C|t=t_1) + p_2 \cdot H(C|t=t_2) + \cdots + p_k \cdot H(C|t=t_{n}) \\
& = \sum_{i=1}^{I} p_i \cdot H(C|t=t_i)
\end{align} \quad (n.ml.1.3.2)
$$假设总样本数有\(m\)条,特征\(t=t_i\)时的样本数\(m_i\),\(p_i=\frac{m_i}{m}\).
接下来,如何求\(P(C|T=t_i)?\)
以二分类为例(正例为1,负例为0),总样本数为\(m\)条,特征\(t\)的取值为\(I\)个,其中特征\(t=t_i\)对应的样本数为\(m_i\)条,其中正例\(m_{i1}\)条,负例\(m_{i0}\)条(即\(m_i=m_{i0} + m_{i1}\))。那么有:
$$
\begin{align}
P(C|T=t_i) & = - \frac{m_{i1}}{m_i} \cdot log_{2} \frac{m_{i1}}{m_i} - \frac{m_{i0}}{m_i} \cdot log_{2} \frac{m_{i0}}{m_i} \\
& = -\sum_{j=0}^{k-1} \frac{m_{ij}}{m_i} \cdot log_{2} \frac{m_{ij}}{m_i}
\end{align} \qquad (n.ml.1.3.3)
$$这里\(k=2\)表示分类的类别数,公式\(\frac{m_{ij}}{m_i}\)物理含义是当\(t=t_i\)且\(C=c_j\)的概率,即条件概率\(p(c_j|t_i)\)。
因此,条件熵计算公式为:
$$
\begin{align}
H(C|t) & = \sum_{i=1}^{I} p(t_i) \cdot H(C|t=t_i) \\
& = - \sum_{i=1}^{I} p(t_i) \cdot \underline { \sum_{j=0}^{k-1} p(c_j|t_i) \cdot log_2 p(c_j|t_i) } \\
& = - \sum_{i=1}^{I} \sum_{j=o}^{k-1} p(c_j,t_i) \cdot log_2 p(c_j|t_i)
\end{align} \qquad (n.ml.1.3.4)
$$
特征\(t\)给系统带来的信息增益等于系统原有的熵与固定特征\(t\)后的条件熵之差,公式表示如下:
$$
\begin{align}
IG(T) & = H(C) - H(C|T) \\
& = -\sum_{i=1}^{k} p(c_i) \cdot \log_{2} p(c_i) + \sum_{i=1}^{n} \sum_{j=1}^{k} p(c_j,t_i) \cdot \log_2 p(c_j|t_i)
\end{align} \qquad(ml.1.3.1)
$$
\(n表示特征t取值个数,k表示类别C个数,\sum_{j=0}^{n-1} \frac{m_{ij}}{m_i} \cdot log_{2} \frac{m_{ij}}{m_i}表示每一个类别对应的熵。\)
下面以天气数据为例,介绍通过信息增益选择最优特征的工作过程:
根据阴晴、温度、湿度和刮风来决定是否出去玩。样本中总共有14条记录,取值为“是”和“否”的yangebnshu分别是9和5,即9个正样本、5个负样本,用\(S(9+,5-)\)表示,S表示样本(sample)的意思。
(1). 分类系统的熵:
$$
Entropy(S) = info(9,5) = -\frac{9}{14} _ log_2 (\frac{9}{14}) - \frac{5}{14} _ log_2 (\frac{5}{14}) = 0.940位 \quad(exp.1.3.1)
$$(2). 如果以特征”阴晴”作为根节点。“阴晴”取值为{sunny, overcast, rainy}, 分别对应的正负样本数分别为(2+,3-), (4+,0-), (3+,2-),那么在这三个节点上的信息熵分别为:
$$
\begin{align}
& Entropy(S| “阴晴”=sunny) = info(2,3) = 0.971位 \quad(exp.1.3.2.1) \\
& Entropy(S| “阴晴”=overcast) = info(4,0) = 0位 \;\;\quad(exp.1.3.2.2) \\
& Entropy(S| “阴晴”=rainy) = info(3,2) = 0.971位 \;\quad(exp.1.3.2.3)
\end{align}
$$以特“阴晴”为根节点,平均信息值(即条件熵)为:
$$
Entropy(S| “阴晴”) = \frac{5}{14} _ 0.971 + \frac{4}{14} _ 0 + \frac{5}{14} * 0.971 = 0.693位 \quad (exp.1.3.2)
$$以特征\( “阴晴”\)为条件,计算得到的条件熵代表了期望的信息总量,即对于一个新样本判定其属于哪个类别所必需的信息量。
(3). 计算特征\( “阴晴”\)对应的信息增益:$$
IG( “阴晴”) = Entropy(S) - Entropy(S| “阴晴”) = 0.247位 \quad(exp.1.3.3.1)
$$同样的计算方法,可得每个特征对应的信息增益,即
$$
IG(“刮风”) = Entropy(S) - Entropy(S|“刮风”) = 0.048位 \qquad\qquad(exp.1.3.3.2) \\
IG(“湿度”) = Entropy(S) - Entropy(S|“湿度”) = 0.152位 \qquad\qquad(exp.1.3.3.3) \\
IG(“温度”) = Entropy(S) - Entropy(S|“温度”) = 0.029位 \qquad\qquad(exp.1.3.3.4)
$$
显然,特征“阴晴”的信息增益最大,于是把它作为划分特征。基于“阴晴”对根节点进行划分的结果,如图4.5所示(决策树学习过程部分)。决策树学习算法对子节点进一步划分,重复上面的计算步骤。
用信息增益选择最优特征,并不是完美的,存在问题或缺点主要有以下两个:
倾向于选择拥有较多取值的特征
尤其特征集中包含ID类特征时,ID类特征会最先被选择为分裂特征,但在该类特征上的分支对预测未知样本的类别并无意义,降低了决策树模型的泛化能力,也容易使模型易发生过拟合。
只能考察特征对整个系统的贡献,而不能具体到某个类别上
信息增益只适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而无法做“本地”的特征选择(对于文本分类来讲,每个类别有自己的特征集合,因为有的词项(word item)对一个类别很有区分度,对另一个类别则无足轻重)。
为了弥补信息增益这一缺点,一个被称为增益率(Gain Ratio)的修正方法被用来做最优特征选择。
增益率
与信息增益不同,信息增益率的计算考虑了特征分裂数据集后所产生的子节点的数量和规模,而忽略任何有关类别的信息。
以信息增益示例为例,按照特征“阴晴”将数据集分裂成3个子集,规模分别为5、4和5,因此不考虑子集中所包含的类别,产生一个分裂信息为:
$$
SplitInfo(“阴晴”) = info(5,4,5) = 1.577位 \qquad(exp.1.3.4)
$$分裂信息熵(Split Information)可简单地理解为表示信息分支所需要的信息量。
那么信息增益率:$$
IG_{ratio}(T) = \frac{IG(T)}{SplitInfo(T)} \qquad(n.ml.1.3.5)
$$在这里,特征 “阴晴”的信息增益率为\(IG_{ratio}( “阴晴”)=\frac{0.247}{1.577} = 0.157\)。减少信息增益方法对取值数较多的特征的影响。
基尼指数(Gini Index)是CART中分类树的特征选择方法。这部分会在下面的“分类与回归树-二叉分类树”一节中介绍。
分类与回归树
分类与回归树(Classification And Regression Tree, 简称CART)模型在Tree-Based家族中是应用最广泛的学习方法之一。它既可以用于分类也可以用于回归,在第06章:Boosting家族的核心成员-Gradient Boosting就是以该模型作为基本学习器(base learner)。
一句话概括CART模型:
| CART模型是在给定输入随机变量\(X\)条件下求得输出随机变量\(Y\)的条件概率分布的学习方法。 |
|---|
在“写在前面”也提到,CART假设决策树时二叉树结构,内部节点特征取值为“是”和“否”,左分支对应取值为“是”的分支,右分支对应为否的分支,如图4.3所示。这样CART学习过程等价于递归地二分每个特征,将输入空间(在这里等价特征空间)划分为有限个字空间(单元),并在这些字空间上确定预测的概率分布,也就是在输入给定的条件下输出对应的条件概率分布。
可以看出CART算法在叶节点表示上不同于ID3、C4.5方法,后二者叶节点对应数据子集通过“多数表决”的方式来确定一个类别(固定一个值);而CART算法的叶节点对应类别的概率分布。如此看来,我们可以很容易地用CART来学习一个
multi-label / multi-class / multi-task的分类任务。
与其它决策树算法学习过程类别,CART算法也主要由两步组成:
- 决策树的生成:基于训练数据集生成一棵二分决策树;
- 决策树的剪枝:用验证集对已生成的二叉决策树进行剪枝,剪枝的标准为损失函数最小化。
由于分类树与回归树在递归地构建二叉决策树的过程中,选择特征划分的准则不同。二叉分类树构建过程中采用基尼指数(Gini Index)为特征选择标准;二叉回归树采用平方误差最小化作为特征选择标准。
二叉分类树
二叉分类树中用基尼指数(Gini Index)作为最优特征选择的度量标准。基尼指数定义如下:
同样以分类系统为例,数据集\(D\)中类别\(C\)可能的取值为\(c_1, c_2, \cdots, c_k\)(\(k\)是类别数),一个样本属于类别\(c_i\)的概率为\(p(i)\)。那么概率分布的基尼指数公式表示为:
$$
Gini(D) = 1 - \sum_{i=1}^{k} {p_i}^2 \qquad(ml.1.3.2)
$$
其中\(p_i = \frac{类别属于c_i的样本数}{总样本数}\)。如果所有的样本类别相同,则\(p_1 = 1, p_2 = p_3 = \cdots = p_k = 0\),则有\( Gini(C)=0\),此时数据不纯度最低。\(Gini(D)\)的物理含义是表示数据集\(D\)的不确定性。数值越大,表明其不确定性越大(这一点与信息熵相似)。
如果\(k=2\)(二分类问题,类别命名为正类和负类),若样本属于正类的概率是\(p\),那么对应基尼指数为:
$$
Gini(D) = 2 p (1-p) \qquad\qquad (n.ml.1.3.6)
$$
如果数据集\(D\)根据特征\(f\)是否取某一可能值\(f_{\ast}\),将\(D\)划分为\(D_1\)和\(D_2\)两部分,即\(D_1=\{(x, y) \in D | f(x) = f_{\ast}\}, D_2=D-D_1\)。那么特征\(f\)在数据集\(D\)基尼指数定义为:
$$
Gini(D, f=f_{\ast}) = \frac{\vert D_1 \vert}{\vert D \vert} Gini(D_1) + \frac{\vert D_2 \vert}{\vert D \vert} Gini(D_2) \qquad\qquad (ml.1.3.3)
$$
在实际操作中,通过遍历所有特征(如果是连续值,需做离散化)及其取值,选择基尼指数最小所对应的特征和特征值。
这里仍然以天气数据为例,给出特征“阴晴”的基尼指数计算过程。
(1). 当特征“阴晴”取值为”sunny”时,\(D_1 = \{1,2,8,9,11\}, |D_1|=5\); \(D_2=\{3,4,5,6,7,10,12,13,14\}, |D_2|=9\)。\(D_1、D_2\)数据自己对应的类别数分别为\((+2,-3)、(+7,-2)\)。因此\(Gini(D_1) = 2 \cdot \frac{3}{5} \cdot \frac{2}{5} = \frac{12}{25} \);\(Gini(D_2) = 2 \cdot \frac{7}{9} \cdot \frac{2}{9} = \frac{28}{81}\). 对应的基尼指数为:
$$
Gini(C, “阴晴”=”sunny”) = \frac{5}{14} Gini(D_1) + \frac{9}{14} Gini(D_2) = \frac{5}{14} \frac{12}{25} + \frac{9}{14} \frac{28}{81} = 0.394 \quad(exp.1.3.5)
$$(2). 当特征“阴晴”取值为”overcast”时,\(D_1 = \{2,7,12,13\}, |D_1|=4\); \(D_2=\{1,2,4,5,6,8,9,10,11,14\}, |D_2|=10\)。\(D_1、D_2\)数据自己对应的类别数分别为\((+4,-0)、(+5,-5)\)。因此\(Gini(D_1) = 2 \cdot 1 \cdot 0 = 0;Gini(D_2) = 2 \cdot \frac{5}{10} \cdot \frac{5}{10} = \frac{1}{2}\). 对应的基尼指数为:
$$
Gini(C, “阴晴”=”sunny”) = \frac{4}{14} Gini(D_1) + \frac{10}{14} Gini(D_2) = 0 + \frac{10}{14} \cdot \frac{1}{2} = \frac{5}{14} = 0.357 \quad(exp.1.3.6)
$$(3). 当特征“阴晴”取值为”rainy”时,\(D_1 = \{4,5,6,10,14\}, |D_1|=5\); \(D_2=\{1,2,3,7,8,9,11,12,13\}, |D_2|=9\)。\(D_1、D_2\)数据自己对应的类别数分别为\((+3,-2)、(+6,-3)\)。因此\(Gini(D_1) = 2 \cdot \frac{3}{5} \cdot \frac{2}{5} = \frac{12}{25} \);\(Gini(D_2) = 2 \cdot \frac{6}{9} \cdot \frac{3}{9} = \frac{4}{9}\). 对应的基尼指数为:
$$
Gini(C, “阴晴”=”sunny”) = \frac{5}{14} Gini(D_1) + \frac{9}{14} Gini(D_2) = \frac{5}{14} \frac{12}{25} + \frac{9}{14} \frac{4}{9} = \frac{4}{7} = 0.457 \quad(exp.1.3.7)
$$
如果特征”阴晴”是最优特征的话,那么特征取值为”overcast”应作为划分节点。
二叉回归树
二叉回归树采用平方误差最小化作为特征选择和切分点选择的依据。一棵回归树对应着特征空间的若干个划分及其在划分单元上的输出值。假设将特征空间划分为\(J\)个单元(子空间),分别是\(\{R_1, R_2, \cdots, R_J\}\),在每个单元\(R_j\)(对应回归树的一个叶子节点)上有一个固定的输出值\(v_j\)(连续变量)。给定训练数据集\(D=\{(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), \cdots, (x^{(m)}, y^{(m)})\}\),二叉回归树模型可表示为:
$$
f(x) = \sum_{j=1}^{J} v_j \cdot I(x \in R_j) \qquad (ml.1.3.4)
$$
\(I(x \in R_j)\)为指示函数,如果输入样本\(x\)属于 \(R_j\)字空间,指示函数为1,对应的输出结果为\(v_j\)。每个输入\(x\)仅对应一个划分单元(字空间)。
当特征空间的划分确定时,用平方误差来表示二叉回归树模型对于训练数据的预测误差,即表示如下:
$$
\hat{v_j} := \arg \min \sum_{x^{(i)} \in R_j} \left(y^{(i)} - f(x^{(i)}) \right)^2 \qquad(ml.1.3.5)
$$
每个单元的最优输出值可通过最小化平方误差求得。易知,划分单元\(R_j\)上的\(v_j\)的最优值\(\hat{v_j}\)是\(R_j\)上的所有输入样本\(x^{(i)}\)对应的输出\(y^{(i)}\)的均值,即\(\hat{c_j} = avg(y^{(i)} | x^{(i)} \in R_j)\)。
下面要解决的问题是:如何划分特征空间?
一个启发式的方式就是选择特征空间中第\(k\)个特征\(f_k\)和它的取值\(s\),作为划分特征和划分点。定义两个区域(对应内部节点两个分支):
$$
R_1(k, s) = \{x \,|\, f_k \le s\}, \quad R_2(k, s) = \{x \,|\, f_k \gt s\} \qquad(n.ml.1.3.7)
$$
然后寻找最优划分特征\(f_k\)和最优划分点\(s\)。具体操作就是遍历所有未划分过的特征集合和对应的取值(集合),求解:
$$
\min_{f_k, \, s} \left[ \min_{v_1} \sum_{x^{(i)} \in R_1(f_k, \, s)} (y^{(i)} - v_1)^2 + \min_{v_2} \sum_{x^{(i)} \in R_2(f_k, \, s)} (y^{(i)} - v_2)^2\right] \qquad(ml.1.3.6)
$$
第1步:固定特征\(f_k\),最小化[ ... ]里的式子可得最优划分点\(s\)。即:
$$
\hat{c_1} = avg (y^{(i)} \,|\, x^{(i)} \in R_1(f_k, s)), \quad \hat{c_2} = avg (y^{(i)} \,|\, x^{(i)} \in R_2(f_k, s)) \qquad(n.ml.1.3.8)
$$
第1步:遍历所有特征集合,寻找最优的划分特征,构成\((f_k, s)\)对。这样就可生成一个内部节点,对应的特征\(f_k\)和划分值\(s\)。依此将特征空间划分为两个区域(对应两个数据子集)。
对每个子区域重复1、2两步的划分过程,直到满足划分停止条件为止(一般的,特征集合\(F = \emptyset\)时)。如此就得到一颗回归树,亦称为最小二乘回归树(Least Squares Regression Tree)。
NEXT \(\cdots\)
- 决策树解读
- 随机森林
参考资料
- 《机器学习导论》
- 《机器学习》-周志华
- 《统计学习方法》
- 《数据挖掘-实用机器学习技术》
更多信息请关注:计算广告与机器学习-CAML 技术共享平台